一、介绍
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
 1.9.0版是Flume的第11版,是Apache顶级项目。Flume 1.9.0是稳定的,可立即投入生产的软件,并且与Flume 1.x代码行的早期版本向后兼容。
此版本进行了几个月的积极开发:自1.8.0版以来,已提交了约70个补丁,代表许多功能,增强功能和错误修复。虽然可以在1.9.0版本页面(下面的链接)上找到完整的更改日志,但这里有一些
1.9.0版是Flume的第11版,是Apache顶级项目。Flume 1.9.0是稳定的,可立即投入生产的软件,并且与Flume 1.x代码行的早期版本向后兼容。
此版本进行了几个月的积极开发:自1.8.0版以来,已提交了约70个补丁,代表许多功能,增强功能和错误修复。虽然可以在1.9.0版本页面(下面的链接)上找到完整的更改日志,但这里有一些
1.1 新功能要点:
1.更好的SSL / TLS支持
2.配置过滤器提供了一种将敏感信息(例如密码)注入配置的方法
3.上下文中的浮点数和双值支持
4.Kafka客户端升级到2.0
5.HBase 2支持
1.2 系统要求
Java运行时环境-Java 1.8或更高版本
内存-足够的内存用于源,通道或接收器使用的配置
磁盘空间-足够的磁盘空间用于通道或接收器使用的配置
目录权限-代理程序使用的目录的读/写权限
二、为什么需要Flume
产生数据的数据端与接收数据的数据端读出和写出的速度不匹配,借助一个中间件来进行缓存数据,稳定数据的输出速度,这就是flume的核心作用。
读数据--->缓存数据【本地磁盘,内存】--->写数据
1.读数据的数据源数据多样:
HDFS、HBase、Mysql、Kafka等等
三、Flume安装
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /root/apps/
配置文件如下:
四、实时采集/root/log/新文件到HDFS
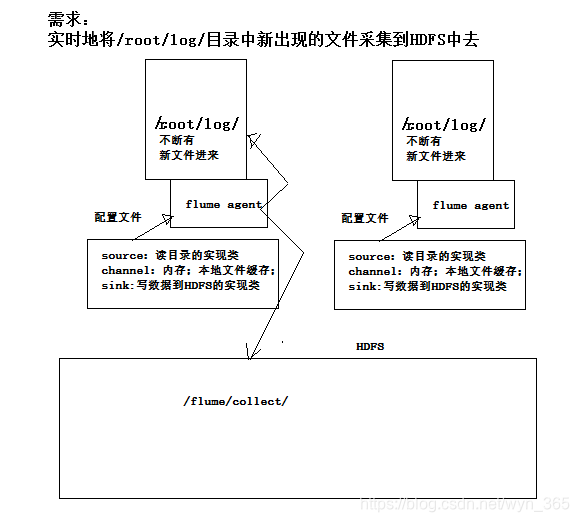
4.1 实时日志
1.创建日志目录
mkdir -p /root/log
2.创建文件
echo 1212312311 -> a.txt
4.2 dir-hdfs.conf
配置文件任何位置都可以
#定义三大组件的名称
ag1.sources = source1
ag1.sinks = sink1
ag1.channels = channel1
# 配置source 【本地磁盘】组件 读取类型 采集目录 采集后的后缀 每行最大长度控制,默认2KB
ag1.sources.source1.type = spooldir
ag1.sources.source1.spoolDir = /root/log/
ag1.sources.source1.fileSuffix=.FINISHED
# ag1.sources.source1.deserializer.maxLineLength=5120
# 配置sink HDFS组件 ## DataStream类型 采集什么,放入什么,还有压缩类型【1100011 1100011 --> 001 001】
ag1.sinks.sink1.type = hdfs
ag1.sinks.sink1.hdfs.path =hdfs://hadoop1:9000/access_log/%y-%m-%d/%H-%M
ag1.sinks.sink1.hdfs.filePrefix = app_log
ag1.sinks.sink1.hdfs.fileSuffix = .log
ag1.sinks.sink1.hdfs.batchSize= 100
ag1.sinks.sink1.hdfs.fileType = DataStream
ag1.sinks.sink1.hdfs.writeFormat =Text
## roll:HDFS 文件滚动切换:控制写文件的切换规则【哪一条满足规则就用哪个】 512M 文件体积切分 100万 条记录 记录切分 60s 切分数据
ag1.sinks.sink1.hdfs.rollSize = 512000
ag1.sinks.sink1.hdfs.rollCount = 1000000
ag1.sinks.sink1.hdfs.rollInterval = 60
## 控制生成 HDFS 目录的规则 10 分钟切换一次
ag1.sinks.sink1.hdfs.round = true
ag1.sinks.sink1.hdfs.roundValue = 10
ag1.sinks.sink1.hdfs.roundUnit = minute
ag1.sinks.sink1.hdfs.useLocalTimeStamp = true
# channel组件配置 50万条记录 flume事务控制所需要的缓存容量600条event记录
ag1.channels.channel1.type = memory
ag1.channels.channel1.capacity = 500000
ag1.channels.channel1.transactionCapacity = 600
# 绑定source、channel和sink之间的连接
ag1.sources.source1.channels = channel1
ag1.sinks.sink1.channel = channel1
4.3 启动flume
nohup bin/flume-ng agent -c conf/ -f dir-hdfs.conf -n ag1 1>/dev/null 2>&1 &
五、文件内容新增追加到HDFS
5.1 整体流程

5.2 tail-hdfs.conf
#定义三大组件的名称
ag1.sources = source1
ag1.sinks = sink1
ag1.channels = channel1
# 配置source 【本地磁盘】组件 读取类型 采集目录 采集后的后缀 每行最大长度控制,默认2KB
ag1.sources.source1.type = exec
a1.sources.r1.command = tail -F /root/access_log.log
# 配置sink HDFS组件 ## DataStream类型 采集什么,放入什么,还有压缩类型【1100011 1100011 --> 001 001】
ag1.sinks.sink1.type = hdfs
ag1.sinks.sink1.hdfs.path =hdfs://hadoop1:9000/access_log/%y-%m-%d/%H-%M
ag1.sinks.sink1.hdfs.filePrefix = app_log
ag1.sinks.sink1.hdfs.fileSuffix = .log
ag1.sinks.sink1.hdfs.batchSize= 100
ag1.sinks.sink1.hdfs.fileType = DataStream
ag1.sinks.sink1.hdfs.writeFormat =Text
## roll:HDFS 文件滚动切换:控制写文件的切换规则【哪一条满足规则就用哪个】 512M 文件体积切分 100万 条记录 记录切分 60s 切分数据
ag1.sinks.sink1.hdfs.rollSize = 512000
ag1.sinks.sink1.hdfs.rollCount = 1000000
ag1.sinks.sink1.hdfs.rollInterval = 60
## 控制生成 HDFS 目录的规则 10 分钟切换一次
ag1.sinks.sink1.hdfs.round = true
ag1.sinks.sink1.hdfs.roundValue = 10
ag1.sinks.sink1.hdfs.roundUnit = minute
ag1.sinks.sink1.hdfs.useLocalTimeStamp = true
# channel组件配置 50万条记录 flume事务控制所需要的缓存容量600条event记录
ag1.channels.channel1.type = memory
ag1.channels.channel1.capacity = 500000
ag1.channels.channel1.transactionCapacity = 600
# 绑定source、channel和sink之间的连接
ag1.sources.source1.channels = channel1
ag1.sinks.sink1.channel = channel1
打印日志 /root/access_log.log
编写shell脚本
while true
do
echo 'date' >> access_log.log
sleep 0.1
done
5.3 启动flume
用tail命令获取数据,下沉到hdfs
启动命令:
bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n ag1
# bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n ag1 -DFlume.root.logger=INFO,console
查看hadoop文件系统有没有
hadoop1:9000
hadoop fs -cat /access_log
六、flume读取本地数据输出到kafka
6.1 Kafka可用于多种情况
1.借助Flume源和接收器-它为事件提供了可靠且高度可用的渠道
2.带有Flume源代码和拦截器,但没有接收器-允许将Flume事件写入 3.Kafka主题,以供其他应用程序使用
4.使用Flume接收器但没有源-这是一种低延迟,容错方式,可将事件5.从Kafka发送到Flume接收器,例如HDFS,HBase或Solr

6.2 flume-kafka.conf
#定义三大组件的名称
ag1.sources = source1
ag1.sinks = sink1
ag1.channels = channel1
# 配置source 【本地磁盘】组件 读取类型 采集目录 采集后的后缀 每行最大长度控制,默认2KB
ag1.sources.source1.type = spooldir
ag1.sources.source1.spoolDir = /root/log/
ag1.sources.source1.fileSuffix=.FINISHED
# ag1.sources.source1.deserializer.maxLineLength=5120
# 配置sink Kafka
ag1.sinks.sink1.channel = c1
ag1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
ag1.sinks.sink1.kafka.topic = mytopic
ag1.sinks.sink1.kafka.bootstrap.servers = localhost:9092
ag1.sinks.sink1.kafka.flumeBatchSize = 20
ag1.sinks.sink1.kafka.producer.acks = 1
ag1.sinks.sink1.kafka.producer.linger.ms = 1
ag1.sinks.sink1.kafka.producer.compression.type = snappy
# channel组件配置 50万条记录 flume事务控制所需要的缓存容量600条event记录
ag1.channels.channel1.type = memory
ag1.channels.channel1.capacity = 500000
ag1.channels.channel1.transactionCapacity = 600
# 绑定source、channel和sink之间的连接
ag1.sources.source1.channels = channel1
ag1.sinks.sink1.channel = channel1
启动flume后,在开启一个kafka消费者就会发现数据消费过来了。 flume官方文档: http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html



评论