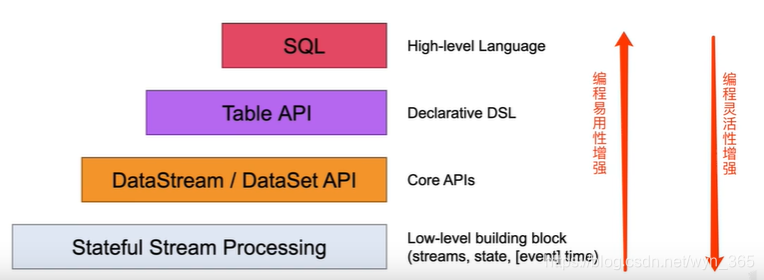
一、 Flink Table API & SQL简介
1.1 Table API & SQL的背景
Flink虽然已经拥有了强大的DataStream/DataSet API,而且非常的灵活,但是需要熟练使用Eva或Scala的编程Flink编程API编写程序,为了满足流计算和批计算中的各种场景需求,同时降低用户使用门槛,Flink供- -种关系型的API来实现流与批的统一,那么这就是Flink的Table & SQL API。
自2015年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于Flink打造新一代计算引擎,针对Flink存在的不足进行优化和改进,并且在2019年初将最终代码开源,也就是我们熟知的Blink。Blink 在原来的Flink基础_上最显著的一个贡献就是Flink SQL的实现。
1.2 Table API & SQL的特点
Table & SQL API是-种关系型API,用户可以像操作mysql数据库表一样的操作数据, 而不需要写java代码完成Flink Function,更不需要手工的优化java代码调优。另外,SQL 作为一个非程序员可操作的语言,学习成本很低,如果一个系统提供SQL支持,将很容易被用户接受。
●Table API & SQL是关系型声明式的,是处理关系型结构化数据的
●Table API & SQL批流统一 ,支持stream流计算和batch离线计算
●Table API & SQL查询能够被有效的优化,查询可以高效的执行
●Table API & SQL编程比较容易,但是灵活度没有DataStream/DataSet API和底层Low-leve |API强
二、离线计算TableAPI & SQL
2.1 ●BatchSQLEnvironmept (离线批处理Table API)
public class BachWordCountSQL {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
DataSet<WordCount> input = env.fromElements(
new WordCount("storm", 1L),
new WordCount("flink", 1L),
new WordCount("hadoop", 1L),
new WordCount("flink", 1L),
new WordCount("storm", 1L),
new WordCount("storm", 1L)
);
tEnv.registerDataSet("wordcount",input,"word,counts");
String sql = "select word,sum(counts) as counts from wordcount group by word" +
"having sum(counts) >=2 order by counts desc";
Table table = tEnv.sqlQuery(sql);
DataSet<WordCount> result = tEnv.toDataSet(table, WordCount.class);
result.print();
}
}
2.2 ●BatchTableEnvironmept (离线批处理Table API)
public class BachWordCountTable {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
DataSet<WordCount> input = env.fromElements(
new WordCount("storm", 1L),
new WordCount("flink", 1L),
new WordCount("hadoop", 1L),
new WordCount("flink", 1L),
new WordCount("storm", 1L),
new WordCount("storm", 1L)
);
Table table = tEnv.fromDataSet(input);
Table filtered = table.groupBy("word")
.select("word,counts.sum as counts")
.filter("counts>=2")
.orderBy("counts.desc");
DataSet<WordCount> wordCountDataSet = tEnv.toDataSet(filtered, WordCount.class);
wordCountDataSet.print();
}
}
执行结果:

三、实时计算TableAPI & SQL
3.1 ●StreamSQLEnvironment (实时流处理Table API)
public class StreamSqlWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.实时的table的上下文
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// socket 数据源[hadoop spark flink]
DataStreamSource<String> lines = env.socketTextStream("192.168.52.200", 8888);
SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
Arrays.stream(line.split(" ")).forEach(out::collect);
}
});
//2.注册成为表
tableEnv.registerDataStream("t_wordcount",words,"word");
//3.SQL
Table table = tableEnv.sqlQuery("SELECT word,COUNT(1) counts FROM t_wordcount GROUP BY word");
//4.结果
DataStream<Tuple2<Boolean, WordCount>> dataStream = tableEnv.toRetractStream(table, WordCount.class);
dataStream.print();
env.execute();
}
}
运行结果如下:

3.2 ●StreamTableEnvironment (实时流处理Table API)
//2.注册成为表
Table table = tableEnv.fromDataStream(words, "word");
Table table2 = table.groupBy("word").select("word,count(1) as counts");
DataStream<Tuple2<Boolean, Row>> dataStream = tableEnv.toRetractStream(table2, Row.class);
dataStream.print();
env.execute();
四、Window窗口和TableAPI & SQL
4.1 Thumb滚动窗口
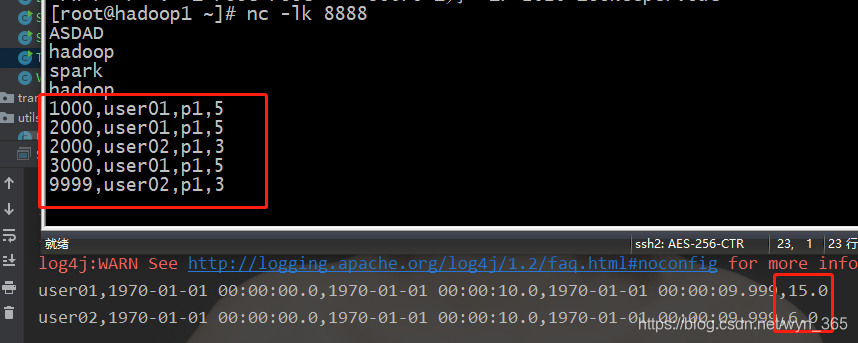
实现滚动不同窗口内相同用户的金额计算,将窗口的起始结束时间,金额相加。
数据如下:
1000,user01,p1,5
2000,user01,p1,5
2000,user02,p1,3
3000,user01,p1,5
9999,user02,p1,3
19999,user01,p1,5
程序如下:
public class TumblingEventTimeWindowTable {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> socketDataStream = env.socketTextStream("192.168.52.200", 8888);
SingleOutputStreamOperator<Row> rowDataStream = socketDataStream.map(new MapFunction<String, Row>() {
@Override
public Row map(String line) throws Exception {
String[] fields = line.split(",");
Long time = Long.parseLong(fields[0]);
String uid = fields[1];
String pid = fields[2];
Double money = Double.parseDouble(fields[3]);
return Row.of(time, uid, pid, money);
}
}).returns(Types.ROW(Types.LONG, Types.STRING, Types.STRING, Types.DOUBLE));
SingleOutputStreamOperator<Row> waterMarkRow = rowDataStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<Row>(Time.seconds(0)) {
@Override
public long extractTimestamp(Row row) {
return (long) row.getField(0);
}
}
);
tableEnv.registerDataStream("t_orders",waterMarkRow,"atime,uid,pid,money,rowtime.rowtime");
Table table = tableEnv.scan("t_orders")
.window(Tumble.over("10.seconds").on("rowtime").as("win"))
.groupBy("uid,win")
.select("uid,win.start,win.end,win.rowtime,money.sum as total");
tableEnv.toAppendStream(table,Row.class).print();
env.execute();
}
}
运行结果如下:
五、Kafka数据源--->Table API & SQL
5.1 KafkaToSQL
public class KafkaWordCountToSql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.connect(new Kafka()
.version("universal")
.topic("json-input")
.startFromEarliest()
.property("bootstrap.servers","hadoop1:9092")
).withFormat(new Json().deriveSchema()).withSchema(new Schema()
.field("name", TypeInformation.of(String.class))
.field("gender",TypeInformation.of(String.class))
).inAppendMode().registerTableSource("kafkaSource");
Table select = tableEnv.scan("kafkaSource").groupBy("gender")
.select("gender,count(1) as counts");
tableEnv.toRetractStream(select, Row.class).print();
env.execute();
}
}



评论