一、实验概述
大数据计算服务(MaxCompute,原名 ODPS)是一种快速、完全托管的 GB/TB/PB 级数据仓库解决方案。MaxCompute 向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
MaxCompute 只能以表的形式存储数据,并对外提供了 SQL 查询功能。用户可以将 MaxCompute 作为传统的数据库软件操作,但其却能处理TB、PB级别的海量数据。需要注意的是,MaxCompute SQL 不支持事务、索引及 Update/Delete 等操作,同时 MaxCompute 的 SQL 语法与 Oracle,MySQL 有一定差别,用户无法将其他数据库中的 SQL 语句无缝迁移到 MaxCompute 上来。此外,在使用方式上,MaxCompute SQL 最快可以在分钟,乃至秒级别完成查询,无法在毫秒级别返回用户结果。MaxCompute SQL 的优点是对用户的学习成本低,用户不需要了解复杂的分布式计算概念。具备数据库操作经验的用户可以快速熟悉 MaxCompute SQL 的使用。
本实验通过实际操作了解有关MaxCompute SQL的相关命令,熟悉MaxCompute SQL ,目前MaxCompute SQL的主要功能包括如下:
1.支持各类运算符
2.通过DDL语句对表、分区以及视图进行管理。
3.通过Select语句查询表中的记录,通过Where字句过滤表中的记录。
4.通过Insert语句插入数据、更新数据。
5.通过等值连接Join操作,支持两张表的关联。支持多张小表的mapjoin。
6.支持通过内置函数和自定义函数来进行计算。
7.支持正则表达式。
二、实验目标
MaxCompute SQL 采用的是类似于 SQL 的语法,可以看作是标准 SQL 的子集,但不能因此简单的把 MaxCompute 等价成一个数据库,它在很多方面并不具备数据库的特征,如事务、主键约束、索引等。本实验的目标是了解MaxCompute SQL 的DML语句(DML:Data Manipulation Language 数据操作语言),包括:SELECT查询、INSERT数据更新、多路输出、表关联JOIN、MAP JOIN、分支条件判断。
完成此实验后,可以掌握的能力有:
1. 如何从MaxCompute中提取数据;
2. 如何更新MaxCompute数据;
3. 掌握通过多路输出,提升数据处理能力、处理速度;
4. MaxCompute如何进行多表关联;
5. MaxCompute中表关联的MAP JOIN处理方式;
6. MaxCompute中表的分支判断处理;
本实验通过控制台Data IDE和客户端两种方式进行实验,学习不同的MaxCompute SQL操作,掌握MaxCompute SQL的编写注意事项。
三、学习建议
1. 掌握MaxCompute的基本概念和术语: 表以及表的DDL操作、项目空间、表的分区等;
2. 熟悉常见的数据类型、MaxCompute支持的数据类型;
3.提前安装 ODPS客户端(下载客户端软件)
(客户端下载地址:https://help.aliyun.com/document_detail/27971.html?spm=5176.doc27834.6.730.xbOX5mS)
第 2 章:背景知识
2.1 背景知识
MaxCompute 主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。随着社会数据收集手段的不断丰富及完善,越来越多的行业数据被积累下来。数据规模已经增长到了传统软件行业无法承载的海量数据(百 GB、TB 乃至 PB)级别。阿里的数加平台Data IDE是一个集成可视化开发环境,构建在阿里云云计算基础设施之上,使用Data IDE能够流畅对接ODPS等计算引擎,可实现数据开发、调度、部署、运维、及数仓设计、数据质量管理等功能;通过Data IDE操作MaxCompute简单方便。
开放实验室是阿里云官方实验平台(https://edu.aliyun.com/lab/),提供真实的阿里云环境、系统的学习进程及课程教材。用户可通过平台自动创建的阿里云资源, 包含自动分配阿里云账号、自动创建的阿里云产品、服务资源和实验指导,深度体验和学习阿里云产品和服务。
2.2 实验操作思路
本实验即通过云中沙箱使用Data IDE和odps客户端学习MaxCompute的操作命令。
首先通过Data IDE 开通实验环境,通过系统分配的项目信息获取AK ID 以及 AK Secret 秘钥对,配置客户端,通过客户端创建实验所需的表和上传实验数据(当然也可以通过Data IDE操作)。
第 3 章:实验环境
3.1 申请MaxCompute资源
弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。 资源创建过程需要1-3分钟。完成实验资源的创建后,用户可以通过 实验资源 查看实验中所需的资源信息,例如:阿里云账号等。
3.2 资源环境准备
友情提示:实验环境一旦开始创建即进入计时阶段,建议学员先了解(学习)实验具体的步骤、目的,真正动手开始做实验时,再进行创建资源,资源一旦创建则中间无法暂停,直至时间消耗完毕。 2.1 资源环境 1)请点击页面左侧的实验资源,在左侧栏中,查看本次实验资源信息。
2)点击“实验资源”,查看所需具体资源,如图案例:
 3)在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。
3)在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。
注意:实验环境一旦开始创建则进入计时阶段,中间无法暂停,时间消耗完毕,则预示着您本次将无法再使用此环境进行具体操作,需重新购买资源或在自己的账户下进行操作。
4)创建资源,如图案例:(创建资源需要几分钟时间,请耐心等候……)
 资源创建成功,如图案例:(注意资源中的项目名称、子用户名称、子用户密码、AK ID、AK Secret信息)
资源创建成功,如图案例:(注意资源中的项目名称、子用户名称、子用户密码、AK ID、AK Secret信息)
这些信息说明参考如图:
 企业别名:即主账号ID(不同的实验企业别名可能不同);子用户名称和子用户密码,登录实验环境 时需要;AK ID和AK Secret是系统为本用户分配的登录验证密钥信息;控制台url即为登录实验环境的地址;
企业别名:即主账号ID(不同的实验企业别名可能不同);子用户名称和子用户密码,登录实验环境 时需要;AK ID和AK Secret是系统为本用户分配的登录验证密钥信息;控制台url即为登录实验环境的地址;
3.3 进入实验环境
如果通过实验环境进行实验在创建资源后,
3.1 、登录控制台(实验环境)
1)登录云中沙箱,在实验目录中查询所需实验,点击进入实验,查看实验所需资源,创建资源成功后,点击实验提供的“控制台url”
(一般建议在另外的浏览器中打开)(具体参考上步实验提供的实验信息,下图为示例参考)
 注意:此实验界面为使用者提供了进入实验的用户名称,如 u-gbecl0av 以及登录密码,请先记录下来,密码需要鼠标点击直接拷贝下来,以及使用其他工具的 AK ID 以及 AK Secret 秘钥对 ,项目名称等信息。将AK ID 和 AK Secret配置在安装的客户端的配置文件中。
注意:此实验界面为使用者提供了进入实验的用户名称,如 u-gbecl0av 以及登录密码,请先记录下来,密码需要鼠标点击直接拷贝下来,以及使用其他工具的 AK ID 以及 AK Secret 秘钥对 ,项目名称等信息。将AK ID 和 AK Secret配置在安装的客户端的配置文件中。
2)输入用户名,案例如图:(说明:@前为子用户名称,假设为“u-bcofvgpr”,@后为企业别名)
3)点击下一步,输入密码:(刚才实验环境创建时所提供)
4)进入控制台界面,点击 “大数据(数加)”
 5) 进入大数据开发控制台,点击”DataWorks”
5) 进入大数据开发控制台,点击”DataWorks”
6) 进入工作区界面,点击“进入数据开发”(某些版本为“进入工作区”)

 7)进入工作环境(首次进入显示每个菜单的帮助信息)
7)进入工作环境(首次进入显示每个菜单的帮助信息)
 8) 点击“跳过”或逐个菜单看看,最终显示
8) 点击“跳过”或逐个菜单看看,最终显示
 9)点击“临时查询”设置实验临时文件
9)点击“临时查询”设置实验临时文件
 10)设置文件名称、类型(选择ODPS SQL)、描述信息(建议非必须)、文件保存目录信息,点击“提交”进入SQL操作环境
10)设置文件名称、类型(选择ODPS SQL)、描述信息(建议非必须)、文件保存目录信息,点击“提交”进入SQL操作环境
 3.2 、配置客户端
3.2 、配置客户端
1)如果为提前安装客户端,请参考下面网址进行安装:
(https://help.aliyun.com/document_detail/27971.html?spm=5176.doc27834.6.730.xbOX5m)
 2)下载客户端案例如图:
2)下载客户端案例如图:
 3)解压安装后如图:
3)解压安装后如图:
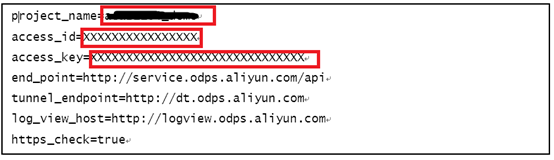
 4)配置客户端文件,在XXX(个人目录)\odpscmd_public\conf\,打开文件 odps_config.ini,修改配置信息;即将上述实验资源中提供的AK ID 以及 AK Secret 和项目名称分别填写在上述配置文件中,其他信息不变,如图
4)配置客户端文件,在XXX(个人目录)\odpscmd_public\conf\,打开文件 odps_config.ini,修改配置信息;即将上述实验资源中提供的AK ID 以及 AK Secret 和项目名称分别填写在上述配置文件中,其他信息不变,如图
 5) 检查测试即通过命令行,进入\ODPS_DEMO\odpscmd_public\bin\,执行 odpscmd,进入交互界面,确认安装是否配置成功。案例如图: (注意操作客户端时,操作命令如果未在自己的环境变量中进行配置需要进入到命令所在的bin目录,操作的文件需要写全文件的目录)
5) 检查测试即通过命令行,进入\ODPS_DEMO\odpscmd_public\bin\,执行 odpscmd,进入交互界面,确认安装是否配置成功。案例如图: (注意操作客户端时,操作命令如果未在自己的环境变量中进行配置需要进入到命令所在的bin目录,操作的文件需要写全文件的目录)
 在bin目录下,输入"odpscmd"回车,执行后进入如下界面:(测试案例项目为bigdata_train)
在bin目录下,输入"odpscmd"回车,执行后进入如下界面:(测试案例项目为bigdata_train)
 6) 通过创建一个数据表测试:
6) 通过创建一个数据表测试:
------输入语句创建表dual ,回车 (注意dual 表后面的实验还会使用,请务必先创建)
create table dual (X string);
------数据表中插入一条记录并检查
insert into table dual select count(*) from dual;

检查插入结果
select * from dual;
 3.3 采用个人账户操作实验
3.3 采用个人账户操作实验
此方式用户需要使用实名认证过的阿里云官网账号登陆阿里云管理控制台,首先开通MaxCompute服务。
(具体开通MaxCompute参照https://help.aliyun.com/document_detail/58226.html?spm=a2c4g.11174283.3.2.qBUiZe )
① 打开浏览器,输入阿里云官网地址 www.aliyun.com:
② 使用自己的阿里云官网账号登陆控制台(示例如图):
 ③ 在控制台左侧导航栏里点击大数据(数加),点击DataWorks,进入工作区登陆页
③ 在控制台左侧导航栏里点击大数据(数加),点击DataWorks,进入工作区登陆页

 选择实验项目(示例为IDE),点击进入工作区进入如下界面
选择实验项目(示例为IDE),点击进入工作区进入如下界面
 注】如果大数据(数加)下没有项目,可以点击控制台中的创建项目,填写相关信息,点击确认即可;如下页面:
注】如果大数据(数加)下没有项目,可以点击控制台中的创建项目,填写相关信息,点击确认即可;如下页面:
 填写项目相关的数据信息:(示意图)
填写项目相关的数据信息:(示意图)
 选择付费方式(根据自己的实际情况),输入自己的项目名称、显示名以及项目描述 ,然后点击确定,创建项目。创建完成进入实验项目工作台。
选择付费方式(根据自己的实际情况),输入自己的项目名称、显示名以及项目描述 ,然后点击确定,创建项目。创建完成进入实验项目工作台。
第 4 章:建表准备数据
4.1 构建实验表
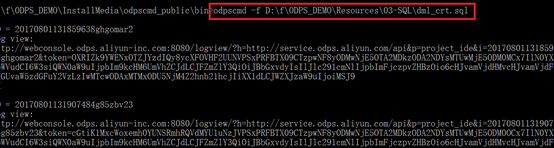
1、 创建实验表: 找到下载文件中的\ODPS_DEMO\resources\03-SQL\dml_crt.sql,执行如下命令(或从附件中直接下载),执行如下命令:
(提示说明:如果下面的命令无法执行,建议将文件、命令路径写全,否则将odpscmd执行命令配置在自己机器的环境变量中) 也可以按绝对路径操作,如图:(odpscmd –f D:\f\ODPS_DEMO\resources\03-SQL\dml_crt.sql –具体实验请调整为自己的目录)
 2、执行完毕,检查表是否存在:[输入:show tables;]
2、执行完毕,检查表是否存在:[输入:show tables;]
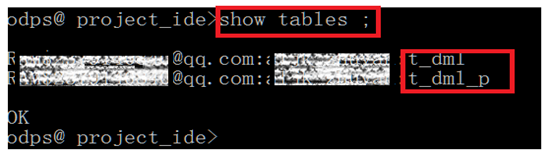 检查表t_dml(一般表),t_dml_p(分区表)是否成功创建,后面实验还会应用 。
检查表t_dml(一般表),t_dml_p(分区表)是否成功创建,后面实验还会应用 。
4.2 加载数据
下载实验附件数据文件t_dml.csv,执行命令如下:(如果出现汉字乱码现象,请注意字符集是否正确)
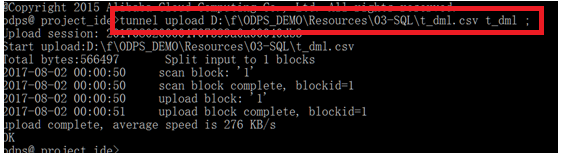
(说明:执行语句建议将自己的命令和文件路径写全,除非你已经将命令配置在环境变量中,在下载的文件目录下执行此命令,另外为避免乱码,建议输入以下命令 tunnel upload 数据文件目录:\t_dml.csv t_dml)
即:tunnel upload XXXXX:\XX\t_dml.csv t_dml ;
tunnel upload D:\f\ODPS_DEMO\Resources\03-SQL\t_dml.csv t_dml;
第 5 章:简单查询
5.1 一般查询
1) 检查表中“浙江省”相关的数据信息 :select * from t_dml where province='浙江省';
(说明:如果出现核查的数据中文出现乱码的现象,建议上传数据时限制字符集合为 -c GBK )
执行效果如图:
 2)核查销售时间大于或等于某日期的数据信息: select city, amt from t_dml where sale_date >='2015-05-23 00:00:00';
2)核查销售时间大于或等于某日期的数据信息: select city, amt from t_dml where sale_date >='2015-05-23 00:00:00';
执行效果如图:
 3)检查总量大于某量的城市信息:select distinct city from t_dml where amt > 700;
3)检查总量大于某量的城市信息:select distinct city from t_dml where amt > 700;

5.2 使用子句的查询
1)统计浙江省销量大于某量的销售城市排名 :
select city,sum(amt) as total_amt
from t_dml
where province='浙江省'
group by city
having count(*)>1 and sum(amt) > 2000
order by total_amt desc
limit 10;
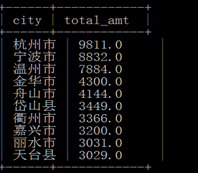 2)城市排名统计
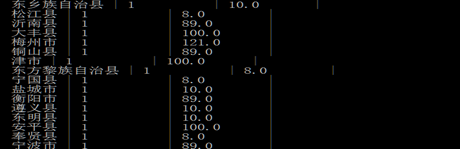
2)城市排名统计
select city, cnt, amt
from t_dml
distribute by city
sort by cnt;
第 6 章:数据更新
6.1 追加记录
1) // insert into table: 追加插入
(提示:本部分使用到表dual ,上面的实验步骤 第3章3小节 已建立,如果未建立此表,请先执行如下语句建立此表:
create table dual (X string); ----创建此表
insert into table dual select count(*) from dual; ---插入一条数据,数值类型会自动转换
select * from dual ; ---检查数据
)
insert into table t_dml select -1,'1900-01-01 00:00:00','','',0,0,0 from dual;
 //检查结果
//检查结果
select * from t_dml where detail_id=-1;
 2)分区表数据操作
2)分区表数据操作
---添加分区:
alter table t_dml_p add if not exists partition (sale_date='2015-01-01');
---往分区添加数据:
insert into table t_dml_p partition (sale_date='2015-01-01')
select -1, '', '', 0, 0, 0 from dual;
 检查数据,结果如图:
检查数据,结果如图:
select * from t_dml_p where sale_date='2015-01-01' ;
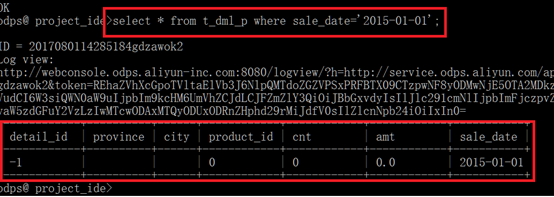
6.2 覆盖插入记录
1)覆盖插入非分区数据表:
insert overwrite table t_dml
select -2,'1900-01-01 00:00:00', '', '',0,0,0 from dual;
select * from t_dml where detail_id in (-1,-2);
(为了编辑方便、直观,我们也可以到控制台上进行处理)如图:
 选中执行操作,执行插入语句,点击“运行”,出现下述系统检查SQL语法界面:
选中执行操作,执行插入语句,点击“运行”,出现下述系统检查SQL语法界面:
 检查无错误,点击“运行”,成功执行出现FINISH
检查无错误,点击“运行”,成功执行出现FINISH
查看结果:(执行选中检查语句 )
select * from t_dml where detail_id in (-1,-2);
 2)分区表数据操作 (依次执行下面的三个操作,添加分区、插入数据、检查分区表数据)
2)分区表数据操作 (依次执行下面的三个操作,添加分区、插入数据、检查分区表数据)
alter table t_dml_p add if not exists partition (sale_date='2015-01-01'); --添加分区
insert overwrite table t_dml_p partition (sale_date='2015-01-01') --插入数据
select -2, '', '', 0, 0, 0 from dual;
select * from t_dml_p where sale_date='2015-01-01' ; ---检查数据
(说明:分区表一般需附带分区条件,避免全分区扫描,在操作未加分区条件的分区表时,MaxCompute提示告警 “full scan with all partitions” )
 3)清空分区表
3)清空分区表
使用覆盖插入的方式清空非分区表
insert overwrite table t_dml select * from t_dml where 1=2; --清空操作
 count t_dml; --核查数据
4)使用覆盖插入的方式清空某个分区
count t_dml; --核查数据
4)使用覆盖插入的方式清空某个分区
insert overwrite table t_dml_p partition(sale_date='2015-01-01')
select detail_id, province, city, product_id, cnt, amt from t_dml_p where 1=2;
 ---检查结果
---检查结果
select count(*) from t_dml_p where sale_date='2015-01-01';
 5) 也可以通过删除分区的方式清空分区
5) 也可以通过删除分区的方式清空分区
alter table t_dml_p drop if exists partition (sale_date='2015-01-01');
select count(*) from t_dml_p where sale_date='2015-01-01';
执行结果如图:
 6)重新加载数据,准备下面的实验(命令示例:Tunnel upload –c GBK “自己的文件目录”\t_dml.csv t_dml ;)
6)重新加载数据,准备下面的实验(命令示例:Tunnel upload –c GBK “自己的文件目录”\t_dml.csv t_dml ;)
第 7 章:多路输出
7.1 实验场景
多路输出即在一个语句中插入不同的结果表或者分区,实验场景说明:
将表 t_dml 中的数据detail_id编号大于5340000的插入一张临时表备查,并将5月1日的记录插入分区表 t_dml_p 的20150501分区中去,将5月2日的数据插入20150502分区,分为三个步骤:
1) 目标表增加分区
2) 备份核查数据
3) 多路输出不同分区
7.2 实验操作
1)增加分区,依次增加两个分区,操作如下
alter table t_dml_p add if not exists partition (sale_date='20150501');
alter table t_dml_p add if not exists partition (sale_date='20150502');
2)创建实验临时表
创建表 create table t_dml_01 like t_dml;
3)将表t_dml中的数据按不同条件同时输出到新建的表和新建的t_dml_p的两个分区中
 参考语句
参考语句
from t_dml
insert into table t_dml_01
select detail_id,sale_date,province,city,product_id,cnt,amt
where detail_id > 5340000
insert overwrite table t_dml_p partition (sale_date='20150501')
select detail_id,province,city,product_id,cnt,amt
where sale_date >= '2015-05-01 00:00:00'
and sale_date <= '2015-05-01 23:59:59'
insert overwrite table t_dml_p partition (sale_date='20150502')
select detail_id,province,city,product_id,cnt,amt
where sale_date >= '2015-05-02 00:00:00'
and sale_date <= '2015-05-02 23:59:59' ;
第 8 章:动态分区
8.1 分区背景
动态分区即分区数值不是直接写死的,是由参数控制或数据中的实际数据控制的。
实际应用中通常会出现类似将表 t_dml 中的数据插入到分区表 t_dml_p中去的现象,由于分区个数多,不能手工逐个处理,太麻烦,需要动态分区。
8.2 分区实验
1)删除上步建立的分区:
alter table t_dml_p drop if exists partition (sale_date='20150501');
alter table t_dml_p drop if exists partition (sale_date='20150502');
 2)利用动态分区直接完成数据插入:
2)利用动态分区直接完成数据插入:
insert into table t_dml_p partition(sale_date)
select detail_id, province, city, product_id, cnt, amt,to_char(sale_date, 'yyyymmdd') as sale_date
from t_dml;
3)利用overwrite 覆盖原来的分区
insert overwrite table t_dml_p partition(sale_date)
select detail_id, province, city, product_id, cnt, amt,
to_char(sale_date, 'yyyymmdd') as sale_date
from t_dml;
第 9 章:join操作
9.1 加载实验数据
1)切换到客户端,切换至目录\ODPS_DEMO\resources\03-SQL(具体目录随自己而定),找到t_product_crt.sql文件,创建表,也可以直接将文件中的内容粘贴到控制台处理(或直接从附件下载实验文件)
(如果执行命令报找不到文件错误,建议执行命令写全路径,示例如下:
自己的目录\odpscmd –f 自己的目录\ODPS_DEMO\resources\03-SQL\t_product_crt.sql )
 执行结果如图:
执行结果如图:
 2) 加载数据 t_product.csv:进入交互界面,加载数据,如下图(目录为参考):
2) 加载数据 t_product.csv:进入交互界面,加载数据,如下图(目录为参考):
(命令示例: tunnel upload 自己的目录盘\ODPS_DEMO\resources\03-SQL\t_product.csv )
9.2 join操作
1) 普通的JOIN操作
业务背景:事实表t_dml包含了销售记录信息,其中字段 product_id为产品标识,可以关联另一张维表t_product获得产品的说明信息,现在想通过SQL得到针对产品大类的销售金额统计:
// 按照产品分类(category_name)统计销售金额
//1-left outer join
select t2.category_name, sum(t1.amt)
from t_dml t1
left outer join t_product t2
on t1.product_id=t2.product_id
group by t2.category_name;
 //2-inner join (join)
//2-inner join (join)
select t2.category_name, sum(t1.amt)
from t_dml t1
inner join t_product t2
on t1.product_id=t2.product_id
group by t2.category_name;
 //3-right outer join
//3-right outer join
select t2.category_name, sum(t1.amt)
from t_dml t1
right outer join t_product t2
on t1.product_id=t2.product_id
group by t2.category_name;

select t1.category_name, sum(t2.amt)
from t_product t1
right outer join t_dml t2
on t1.product_id=t2.product_id
group by t1.category_name;
 //4-full outer join
//4-full outer join
select t2.category_name, sum(t1.amt)
from t_dml t1
full outer join t_product t2
on t1.product_id=t2.product_id
group by t2.category_name;

第 10 章:MapJoin HINT
10.1 场景介绍
由于各种原因,造成销售信息表 t_dml 中的记录存在一些质量问题,可能的问题包括:
1- 产品标识错误: 可以通过单价判断,单价相等的标识不同,则可能存在错误
2- 价格错误:如果销售记录中的平均单价高于产品维表中的定价,则可能存在问题
请协助发现这些可能存在问题的记录。
10.2 MapJoin HINT操作
1) left outer join 实现质量问题
select /*+mapjoin(t2)*/t1.*,t1.amt/t1.cnt,t2.product_id,t2.price
from t_dml t1
left outer join t_product t2
on t1.product_id<>t2.product_id
and t1.amt/t1.cnt = t2.price
where t2.price is not null;
 2)inner join (join) 实现质量问题
2)inner join (join) 实现质量问题
select /*+mapjoin(t1)*/ t1.*, t1.amt/t1.cnt,t2.product_id, t2.price
from t_dml t1
inner join t_product t2
on t1.product_id=t2.product_id
or t1.amt/t1.cnt - t2.price < 0.01;
 3)right outer join: 重写left outer join实现的逻辑
3)right outer join: 重写left outer join实现的逻辑
select /*+mapjoin(t1)*/t2.*,t2.amt/t2.cnt,t1.product_id,t1.price
from t_product t1
right outer join t_dml t2
on t1.product_id<>t2.product_id
and t2.amt/t2.cnt = t1.price
where t1.price is not null;
 注意:在做关联时,如果关联条件比较复杂(比如包含 or 等连接条件)或者是关联条件中存在非等值关联(比如大于、小于或者不等于等),则普通的 join 无法实现,可以采用带有 mapjoin HINT 的 join 方式。
注意:在做关联时,如果关联条件比较复杂(比如包含 or 等连接条件)或者是关联条件中存在非等值关联(比如大于、小于或者不等于等),则普通的 join 无法实现,可以采用带有 mapjoin HINT 的 join 方式。
第 11 章:子查询
11.1 简单查询
ODPS SQL 支持将子查询作为一张表来用,可以用于简单查询、join等。在使用中,必须为子查询指定别名。
子查询用于简单查询,如:
select * from (select distinct province from t_dml) t;
执行结果:

11.2 join子查询
1) 子查询用于join
select t2.category_name, sum(t1.amt)
from (select * from t_dml where amt > 800) t1
inner join t_product t2
on t1.product_id=t2.product_id
group by t2.category_name;
 2) 子查询用于mapjoin
2) 子查询用于mapjoin
select /*+mapjoin(t1)*/t2.*,t2.amt/t2.cnt,t1.product_id,t1.price
from t_product t1
right outer join (select * from t_dml where detail_id > 5340000) t2
on t1.product_id=t2.product_id
and t2.amt/t2.cnt <> t1.price
where t1.price is not null;

第 12 章:SQL联合与条件表达式
12.1 联合处理UNION ALL
在销售记录中,由于实际售卖价钱和产品的标称价并不一致,如果想获得产品的所有出现过的单价(包括实际售卖价和标称价),则采用如下语句处理:
select * from (
select product_id,price, 'STD' type from t_product
UNION ALL
select distinct product_id, amt/cnt as price, 'USED' type from t_dml
) t
order by product_id,type,price desc
limit 100;

12.2 条件表达式CASE WHEN
如果市场部准备做一次市场营销活动,对于一次购买3-5个产品的,在目前的售价上实行9折优惠,一次购买6个及以上产品的,给与8折优惠。请基于5月份数据想评估一下此次活动的成本(为了简单可行,活动成本定义为目前销售额减掉优惠后的销售额)。则处理语句如下:
select sum(amt)-sum(case when cnt>=6 then amt*0.8
when cnt>=3 then amt*0.9
else amt
end) cost
from t_dml;

第 13 章:SQL执行结果的验证
13.1 简单SQL通过结果直接验证
简单SQL通过执行结果判定是否正确,如通过简单查询语句验证:
如验证分区是否存在:
select * from t_dml_p where sale_date='20150501' ;
 数据显示,表明SQL正常执行。
数据显示,表明SQL正常执行。
13.2 复杂SQL验证
复杂SQL不容易理解或从结果中无法直接得到信息,采用逆向抽样的方法,如上述实验中涉及到的,利用动态分区快速插入数据
insert into table t_dml_p partition(sale_date)
select detail_id, province, city, product_id, cnt, amt,
to_char(sale_date, 'yyyymmdd') as sale_date
from t_dml;
1)先检查分区是否存在
 2)执行删除分区的操作
2)执行删除分区的操作
alter table t_dml_p drop if exists partition (sale_date='20150501');
 3)核查操作结果,则需要进行抽样验证,上步操作即检查删除的分区是否存在
3)核查操作结果,则需要进行抽样验证,上步操作即检查删除的分区是否存在
如:
select * from t_dml_p where sale_date ='抽样数据' (sale_date=‘20150101’)

第 14 章:课后任务
14.1 课后任务
思考题 :
在常规的数据需求中,通常会遇到类似的统计查询,从一个千万级别甚至上亿级别的记录表中,将数据按不同条件分散到不同的表中,如按省份将各省数据分装到不同的表中,如果数据源表在MaxCompute中,采用哪种方式比较简单?相反如果统计所有省的数据,每个省数据放置在不同表中或不同分区中,考虑这样又如何做,效率如何?
课后练习:
假设一个学生期末考试成绩单,包含学号、课程、课程得分三列信息,请写出按每个课程的学生成绩排名?



评论