一、 实验概述
DataWorks (数据工场,原大数据开发套件DataIDE),是基于MaxCompute(原ODPS) 计算引擎的一站式大数据开发管理的平台,它融合了数据集成、数据开发、数据管理、运维监控、机器学习等功能,提供了海量数据的离线加工分析、数据挖掘的能力,能帮助企业快速的搭建数据中心。
二、实验目标
1)通过创建项目、同步数据、编写SQL程序、配置调度任务、运维监控等环节,实现完整的数据处理流程。
2)能对DataWorks的主要功能有所了解,能够按照实验演示内容,独立完成数据采集 、数据开发、任务运维等数据岗位常见的任务。
三、 实验场景
模拟RDS数据库为生产系统,实现从生产系统抽取数据到ODPS中,进行数据自动化分析处理,最后展现处理结果。
第 1 章:实验准备
1.1 申请阿里云资源
在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。 资源创建过程需要1-3分钟。完成实验资源的创建后,用户可以通过 实验资源 查看实验中所需的资源信息,例如:阿里云账号等。
1.2 申请实验资源
1、 申请沙箱实验资源
1)点击【实验资源】,查看本次实验资源信息(MaxCompute资源、RDS资源)。如下图:
 2)在弹出的左侧栏中,点击 【创建资源】按钮,开始创建实验资源。 如下图:
2)在弹出的左侧栏中,点击 【创建资源】按钮,开始创建实验资源。 如下图:
注意:实验环境一旦开始创建则进入计时阶段,建议学员先基本了解实验具体的步骤、目的,真正开始做实验时再进行创建。
3)创建资源,如下图:(创建资源需要几分钟时间,请耐心等候……)
4)资源创建成功后,可通过【实验资源】查看实验中所需的实验资源信息。如下图:
注意:在本地保存下阿里云账号信息,包括资源中的项目名称、企业别名、子用户名称、子用户密码、AK ID、AK Secret信息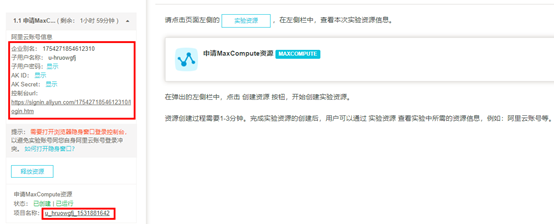 沙箱实验环境说明:
沙箱实验环境说明:
企业别名:即主账号ID,在登录时需要;
子用户名称和子用户密码:登录实验环境以及配置MaxCompute 数据源时需要;
AK ID和AK Secret:系统为当前用户分配的登录验证密钥信息;
控制台url:登录实验环境的地址;
实验数据库RDS实例:在配置 MaxCompute 数据源时需要;
实验数据库RDS链接地址:为登录数据库的地址信息。
1.3 登录实验环境
1、使用实验沙箱登录
1)点击实验资源中的【控制台url】,复制链接,在新的窗口打开,跳转到登录页。
 2)在登录页,输入【实验资源】中提供的账号,格式为:子用户名称@企业别名,再点击【下一步】。如下图:
2)在登录页,输入【实验资源】中提供的账号,格式为:子用户名称@企业别名,再点击【下一步】。如下图:
 3)输入【实验资源】中提供的的“子用户密码”,点击【登录】
4)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】
5) 选中相应项目, 点击【进入数据开发】
6) 进入数据开发环境
3)输入【实验资源】中提供的的“子用户密码”,点击【登录】
4)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】
5) 选中相应项目, 点击【进入数据开发】
6) 进入数据开发环境
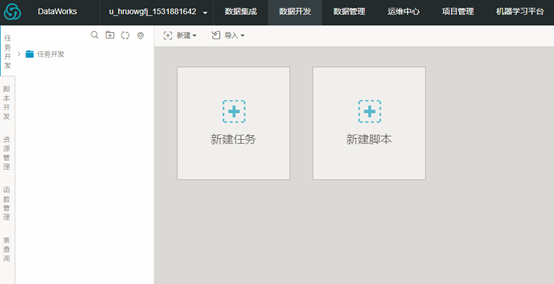 2、使用阿里云账号登录
2、使用阿里云账号登录
1) 打开浏览器,输入阿里云官网地址 www.aliyun.com,点击右上角菜单【控制台】:
2)使用自己的阿里云官网账号登陆控制台,如果没有账号,请先实名注册:
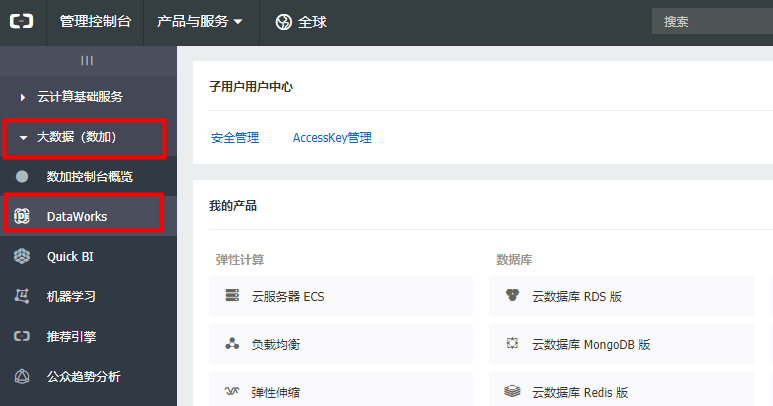
 3)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】
3)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】
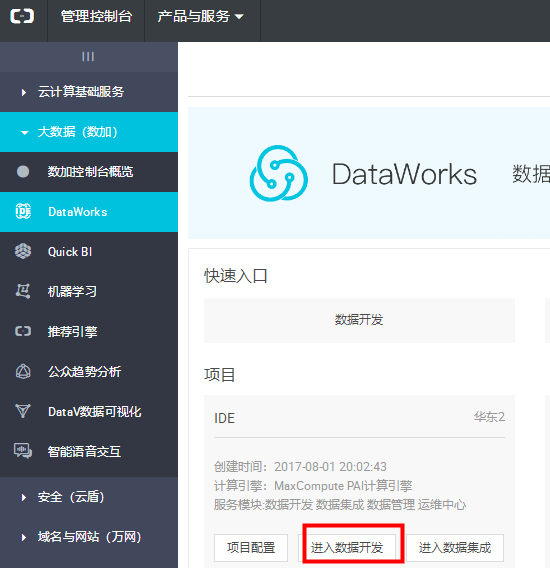
 4)选中相应项目, 点击【进入数据开发】。如果没有项目,请先创建项目。
4)选中相应项目, 点击【进入数据开发】。如果没有项目,请先创建项目。
第 2 章:实验详情
2.1 创建项目
1、创建项目 注意:DataWorks是项目协作模式,只有阿里云主账号可以创建项目,其他子账号仅作为使用者在项目中操作。因沙箱实验环境限制,用户使用子账号登录,无权限创建项目。故实验环境已默认创建完项目,此章节内容仅供了解。
如果没有项目,创建项目步骤如下:
1)进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】,然后在【项目列表】中选择区域,再点击【创建项目】。如下图:
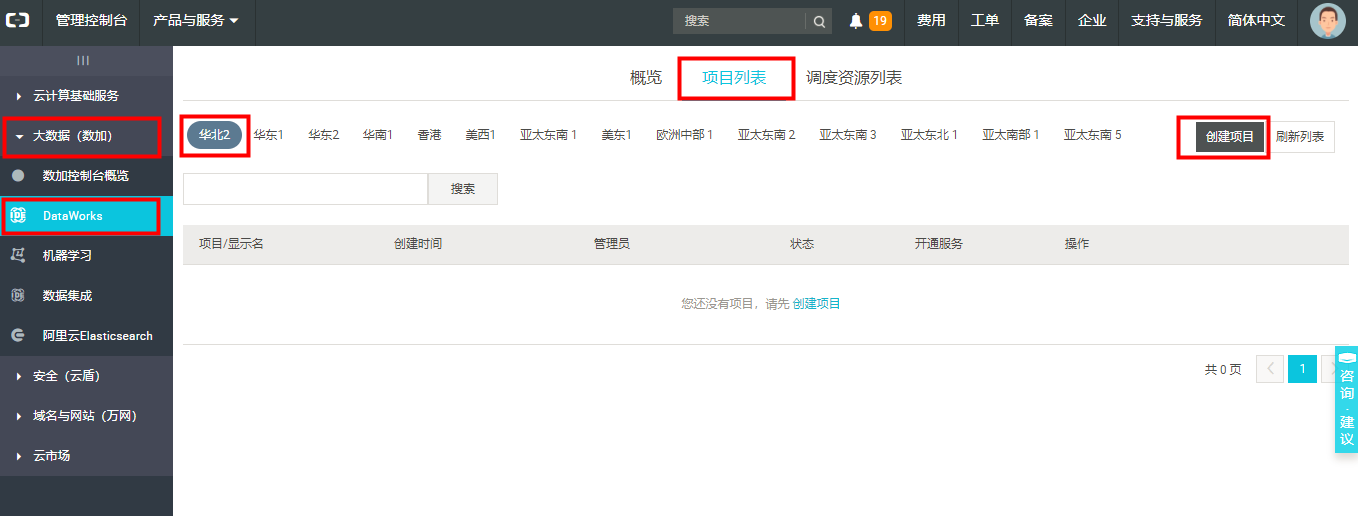 2)选择region、计算引擎服务、DataWorks服务,付费方式根据自己的实际情况选择,然后点击【下一步】:
2)选择region、计算引擎服务、DataWorks服务,付费方式根据自己的实际情况选择,然后点击【下一步】:
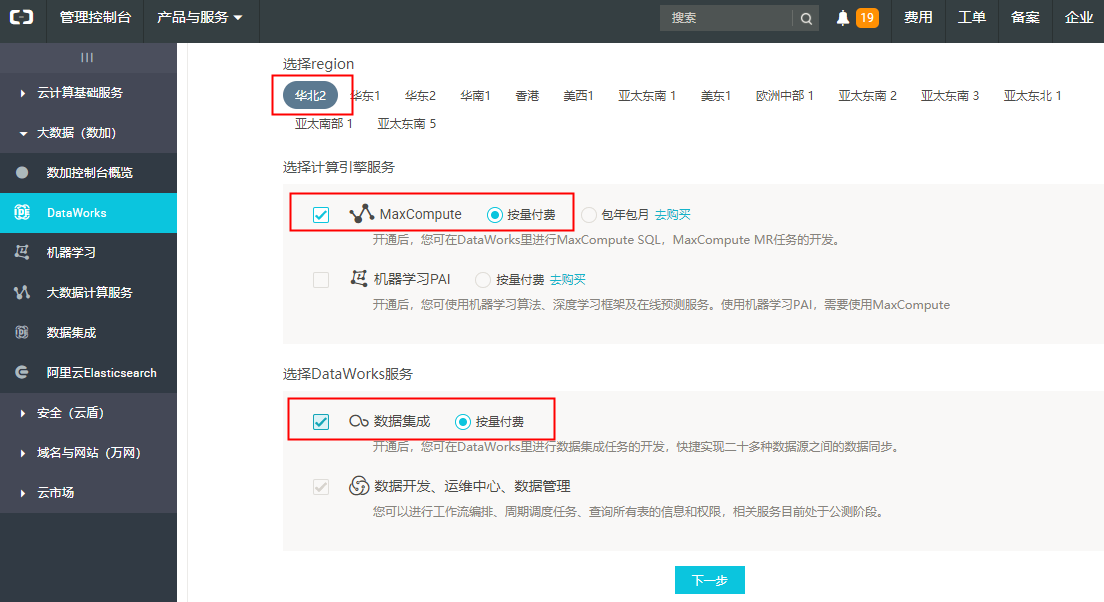 3)填写项目相关信息:输入“项目名称”、“显示名”以及“项目描述” 信息,然后点击【创建项目】。
3)填写项目相关信息:输入“项目名称”、“显示名”以及“项目描述” 信息,然后点击【创建项目】。
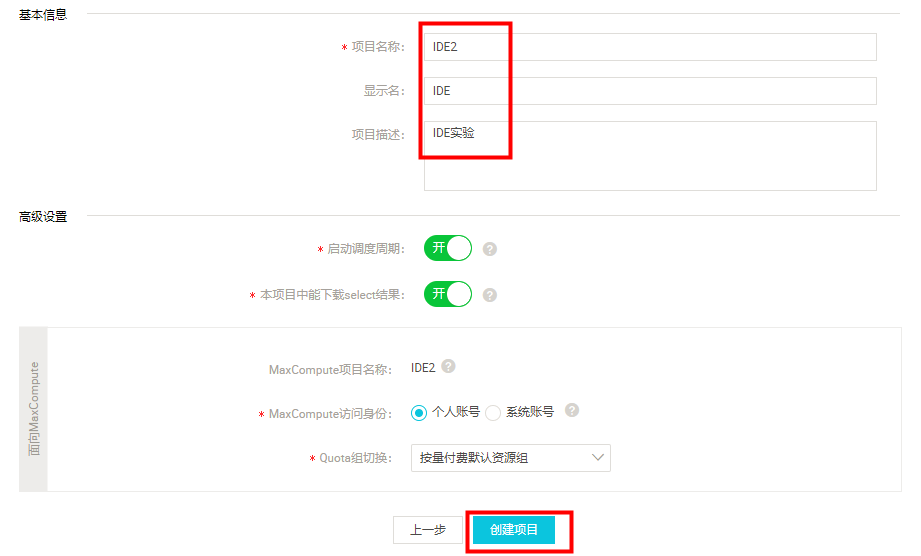 4)创建项目成功后,点击【刷新列表】,即可看到项目列表,如下图
4)创建项目成功后,点击【刷新列表】,即可看到项目列表,如下图
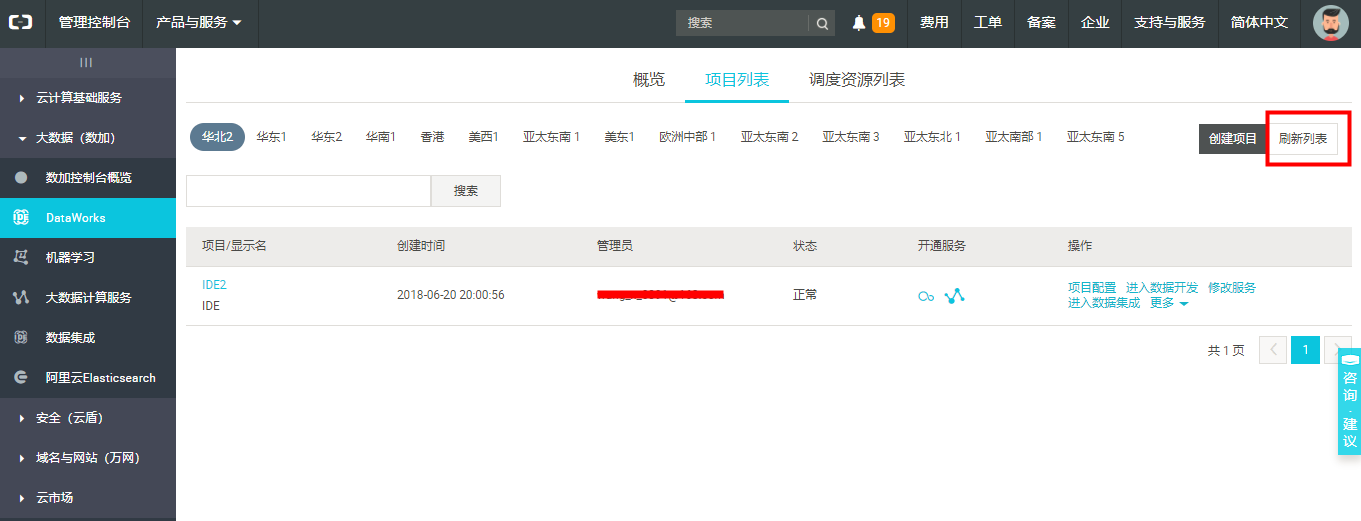 5)在【项目列表】页签中,选中项目,点击【进入数据开发】按钮,开始数据开发工作。
5)在【项目列表】页签中,选中项目,点击【进入数据开发】按钮,开始数据开发工作。
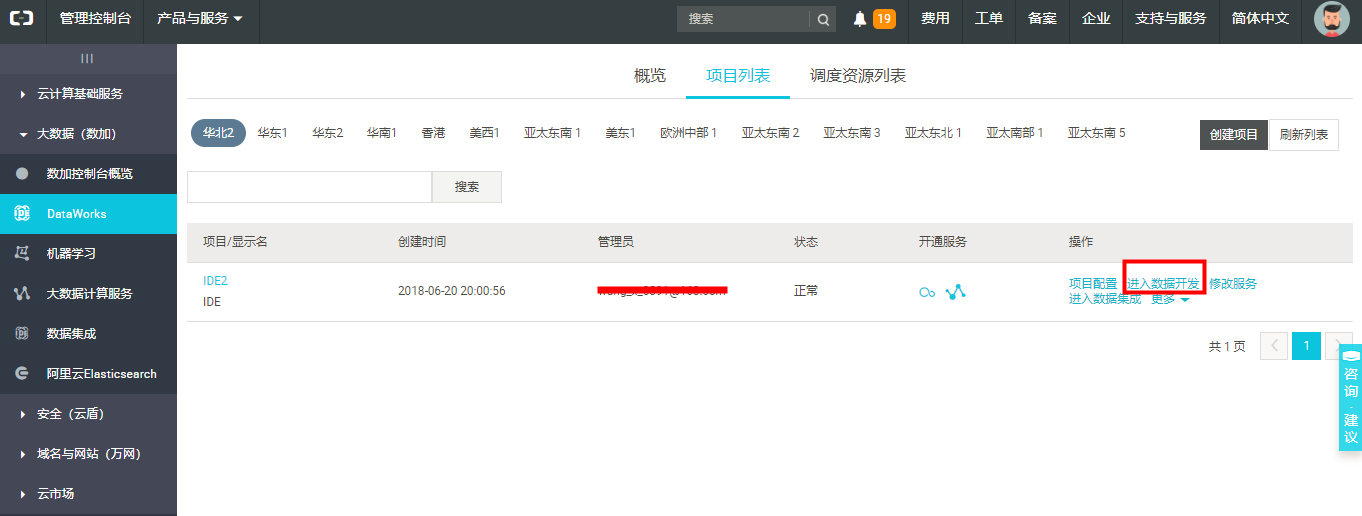 也可点击【概览】,选中项目,点击【进入数据开发】按钮,开始数据开发工作。
也可点击【概览】,选中项目,点击【进入数据开发】按钮,开始数据开发工作。
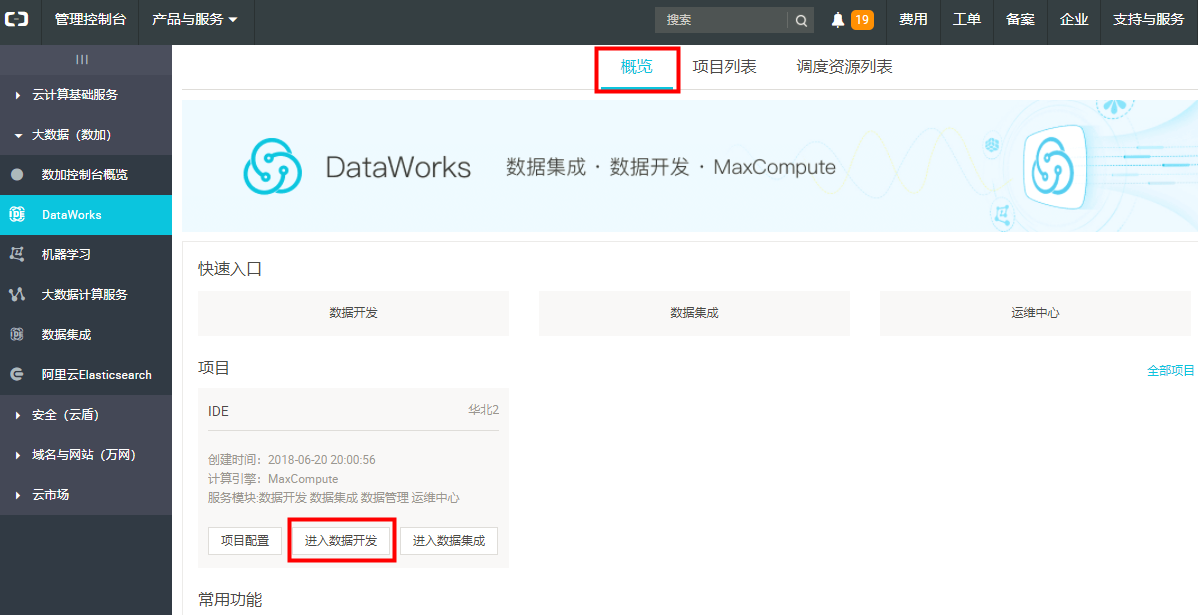
 6)初次打开需勾上协议条款,点击【确认】,然后进入数据开发页面
6)初次打开需勾上协议条款,点击【确认】,然后进入数据开发页面
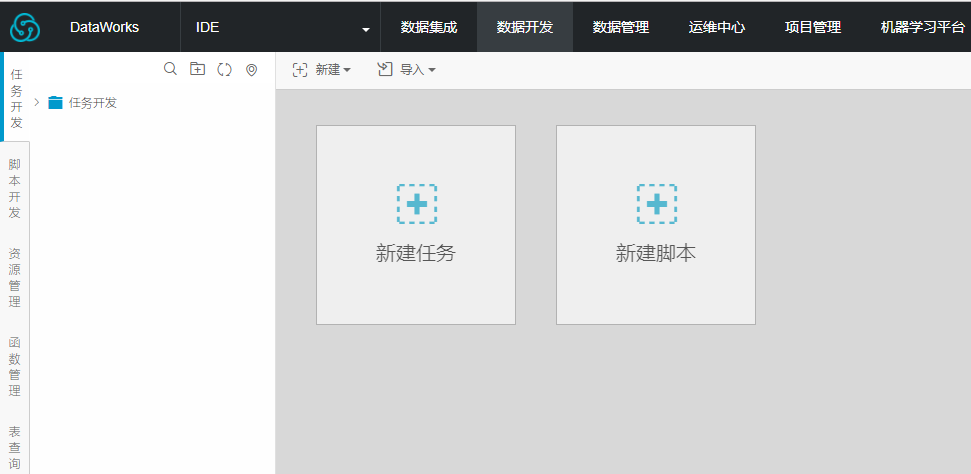
2.2 创建RDS数据库
说明:本实验利用阿里云RDS数据库,模拟构建生产系统。沙箱实验环境中已默认创建完RDS数据库实例,下面1)小节仅参考,直接进行 2)小节
1)创建RDS数据库实例:
打开【管理控制台】,在左侧菜单栏中,点击【云计算基础服务】,在下拉菜单中点击【云数据库RDS版】,然后点击右上角的【创建实例】按钮。
 依次选择“付费类型”(按量付费)、“地域”(按照实验资源分配地区)以及“数据库类型”(MySQL)、“版本”(5.7)、“系列”(高可用版)、“可用区信息”(华东2可用区B):
依次选择“付费类型”(按量付费)、“地域”(按照实验资源分配地区)以及“数据库类型”(MySQL)、“版本”(5.7)、“系列”(高可用版)、“可用区信息”(华东2可用区B):
 选择“网络类型”(经典网络)、“规格”(1核1GB)、“存储空间” (最小5GB)、“数量”(选择1)
选择“网络类型”(经典网络)、“规格”(1核1GB)、“存储空间” (最小5GB)、“数量”(选择1)
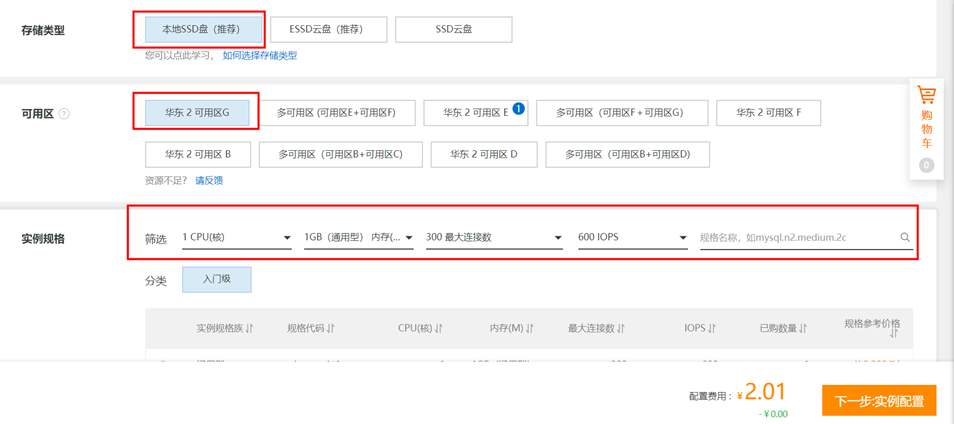
 点击确认订单,点击进入【管理控制台】,等待实例由“创建中”变成“运行中” (此过程需要几分钟,请耐心等待)
点击确认订单,点击进入【管理控制台】,等待实例由“创建中”变成“运行中” (此过程需要几分钟,请耐心等待)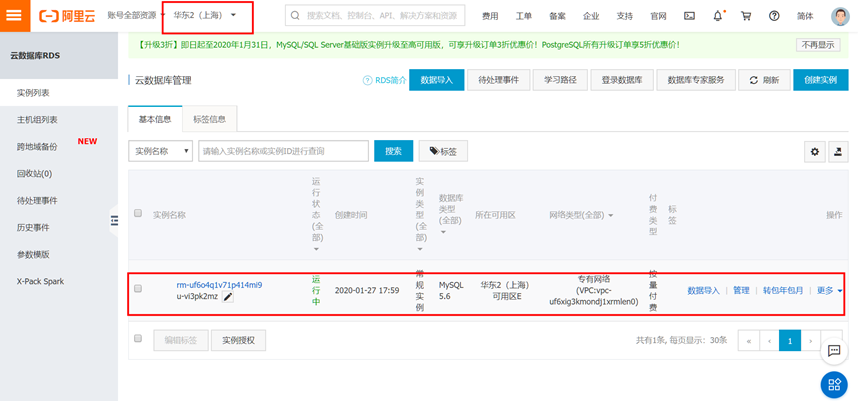 2) 创建数据库
2) 创建数据库
点击左侧栏数据库管理,点击创建数据库按钮
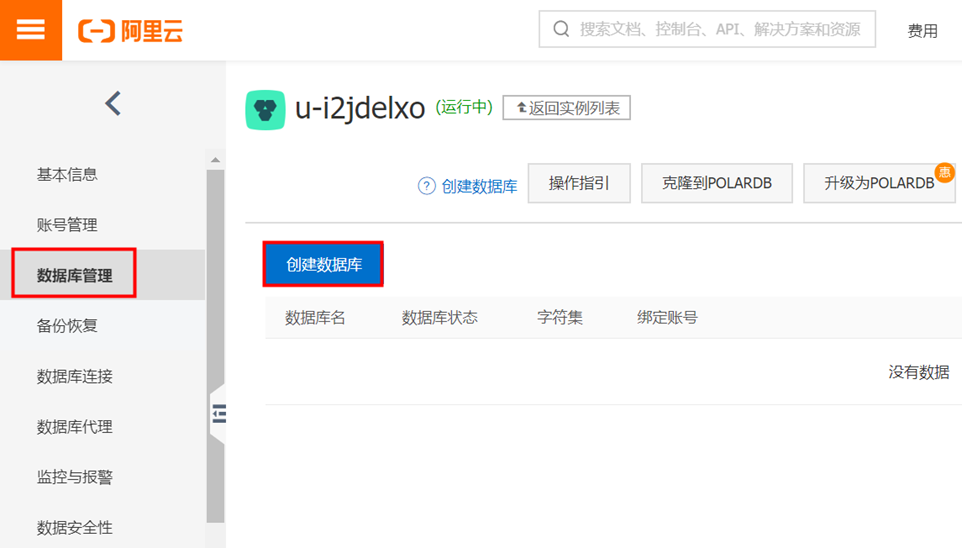 输入“数据库名称”(自行命名)、选择“支持字符集合”(实验选择“utf8”)等信息,点击【创建】按钮
输入“数据库名称”(自行命名)、选择“支持字符集合”(实验选择“utf8”)等信息,点击【创建】按钮
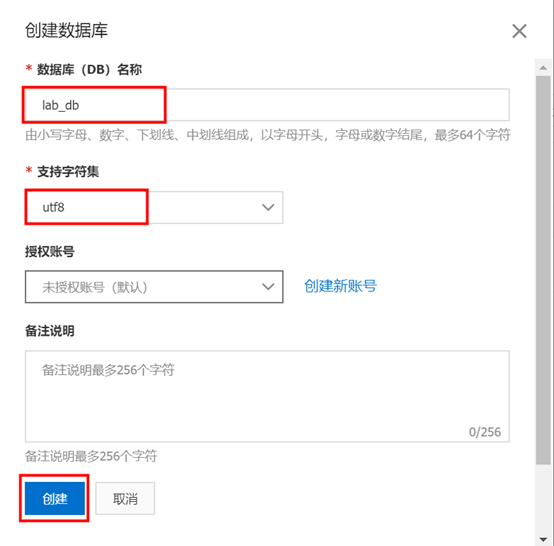 3) 创建数据库账号
3) 创建数据库账号
点击左侧菜单栏中的【账号管理】,进入 “创建账号” 界面
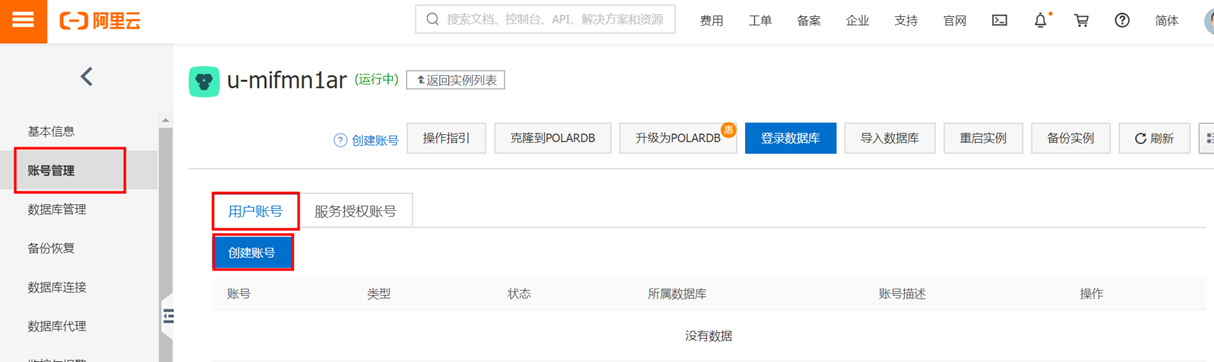 具体创建账号参考示例:
具体创建账号参考示例:
① 输入自定义“数据库账号”、账号类型选择“普通账号” 选择“授权数据库”、自行“设置密码”、“确认密码” 然后点击确定。
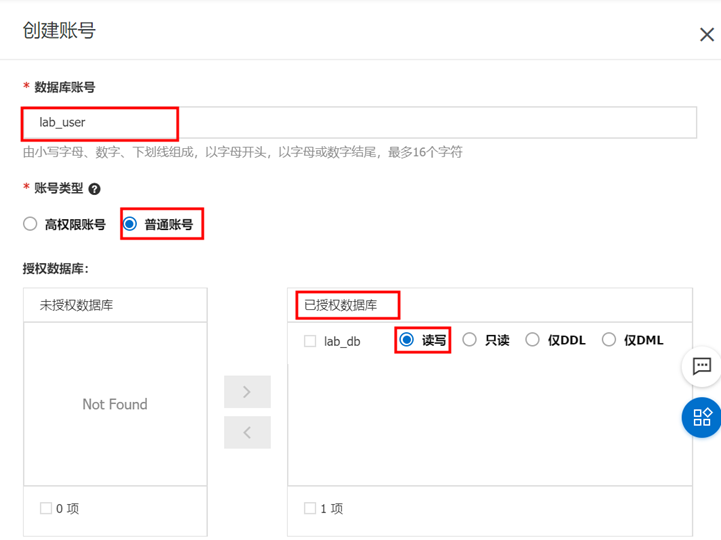 ② 点击【确定】,等待系统处理:
② 点击【确定】,等待系统处理:
③ 账号状态变更为“激活”,类型为“普通账号”,所属数据库为lab_db,拥有读写权限:
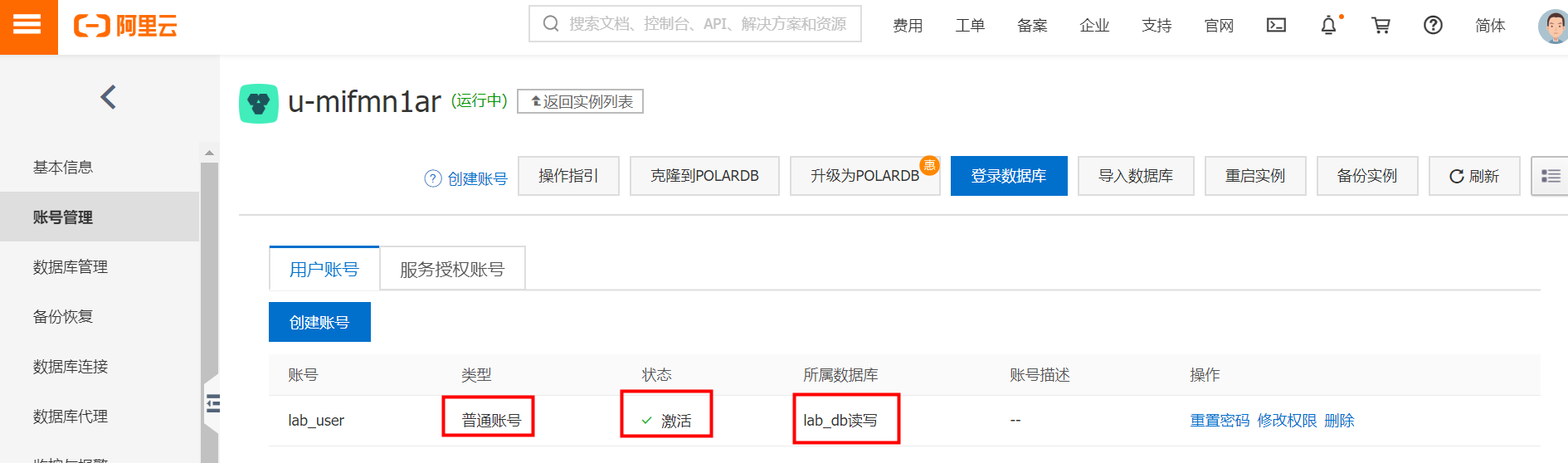 4) 登录数据库
4) 登录数据库
点击产品与服务,选择数据管理DMS。
 选择左侧栏中快捷登录,RDS登录。(注意:如果出现授权提示,点击关闭比即可)
选择左侧栏中快捷登录,RDS登录。(注意:如果出现授权提示,点击关闭比即可)
 输入网络地址:端口、用户名、用户密码(实验中新建的数据库用户及对应密码)
输入网络地址:端口、用户名、用户密码(实验中新建的数据库用户及对应密码)
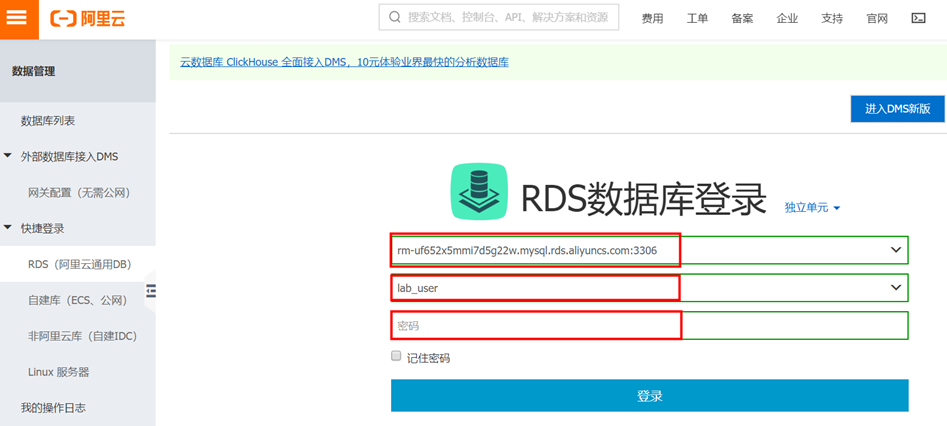 网络地址为RDS实例的内网链接地址:端口格式填入。
网络地址为RDS实例的内网链接地址:端口格式填入。
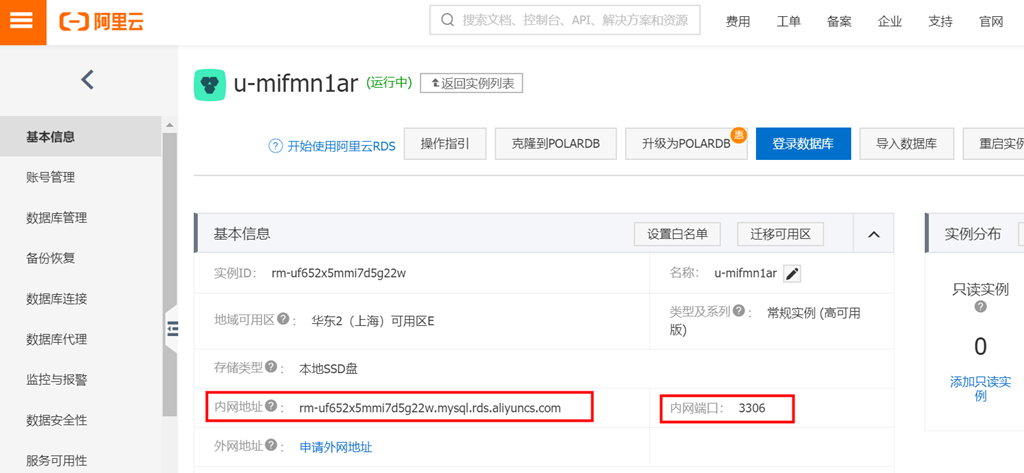 输入完成点登录,即可访问数据库操作工作台,可执行相关操作
输入完成点登录,即可访问数据库操作工作台,可执行相关操作
2.3 RDS数据导入
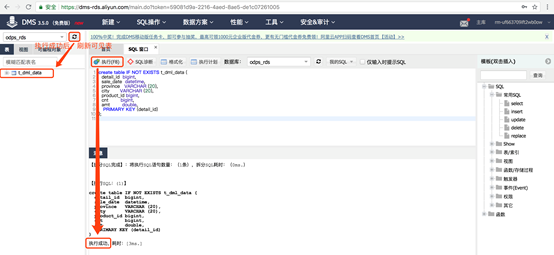
1)新建表。
登录RDS数据库,在顶部菜单栏中,点击【SQL操作】,然后点击下拉列表中的【SQL窗口】。
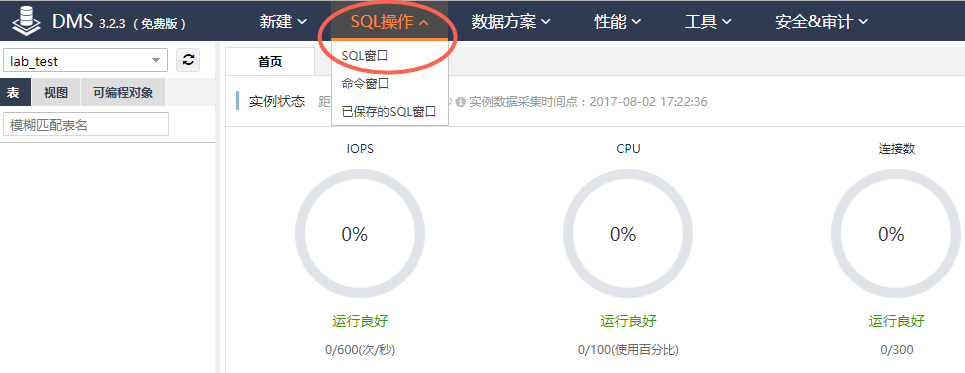 输入SQL建表语句,创建表t_dml_data,用于模拟存储业务系统的生产数据。
输入SQL建表语句,创建表t_dml_data,用于模拟存储业务系统的生产数据。
建表语句如下:
create table IF NOT EXISTS t_dml_data (
detail_id bigint,
sale_date datetime,
province VARCHAR (20),
city VARCHAR (20),
product_id bigint,
cnt bigint,
amt double,
PRIMARY KEY (detail_id)
);
点击【执行】,建表成功后刷新左侧列表,窗口可显示刚建的表。
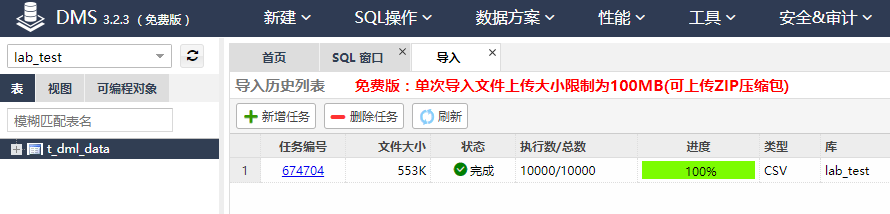
 2)导入数据
2)导入数据
点击顶部菜单栏的【数据方案】,在下拉列表中点击【导入】。
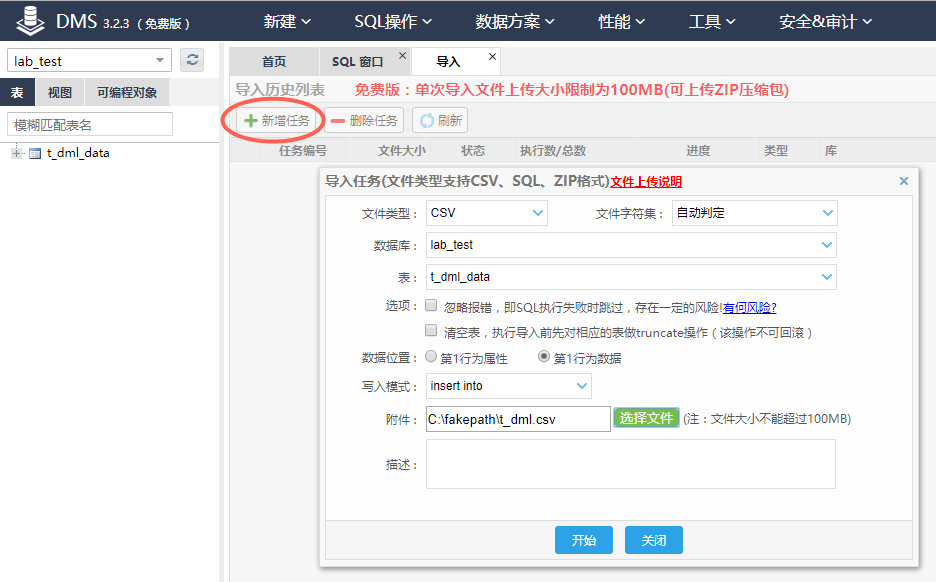
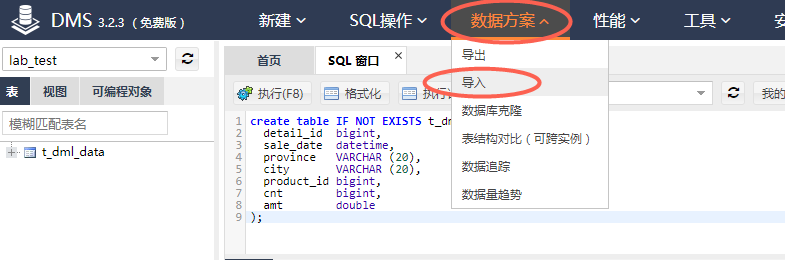 点击【新增任务】,填写“文件类型”、“数据库”、“表”、“写入模式”、“附件”等信息,然后点击【开始】,执行数据导入任务。(注意:如果导入失败,请将文件字符集改为UTF-8格式重新导入)
点击【新增任务】,填写“文件类型”、“数据库”、“表”、“写入模式”、“附件”等信息,然后点击【开始】,执行数据导入任务。(注意:如果导入失败,请将文件字符集改为UTF-8格式重新导入)
 如下图,导入任务完成后,会显示数据导入详情。
如下图,导入任务完成后,会显示数据导入详情。
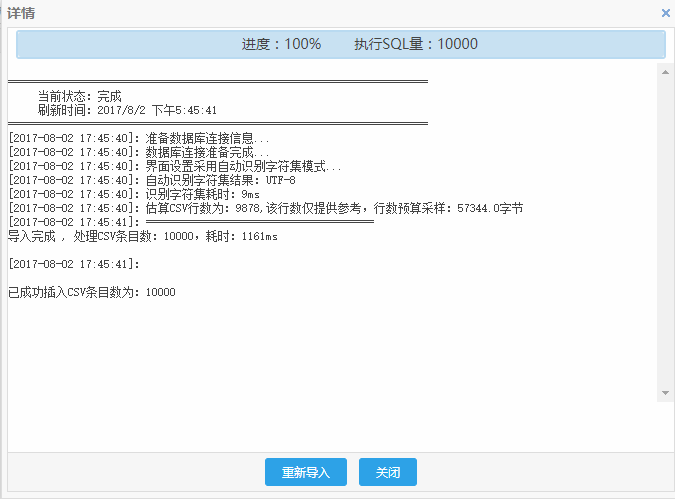 关闭详情,可看到该任务。
关闭详情,可看到该任务。
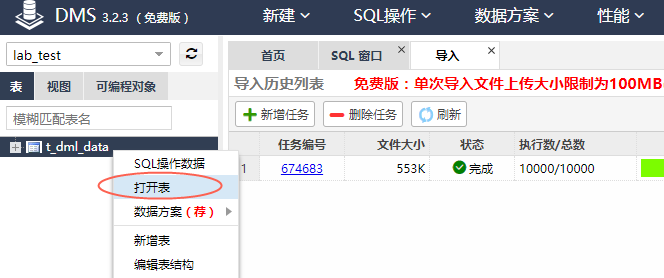
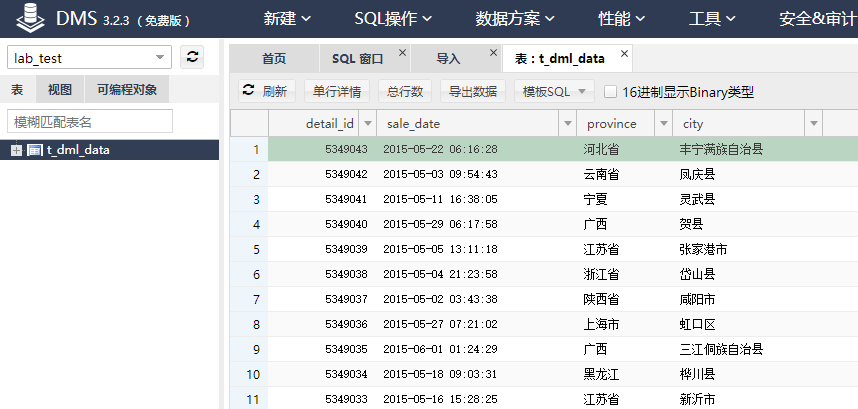
 击左侧树中的表名,选择【打开表】,可看到表中的数据信息
击左侧树中的表名,选择【打开表】,可看到表中的数据信息
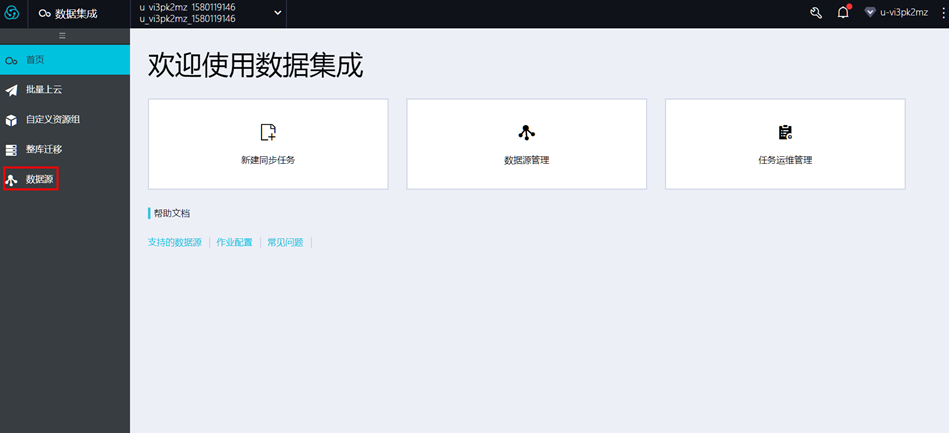
2.4 DataWorks数据集成
2、DataWorks数据集成 注意: 只有项目管理员角色才能新增数据源,其他角色的成员仅能查看数据源。
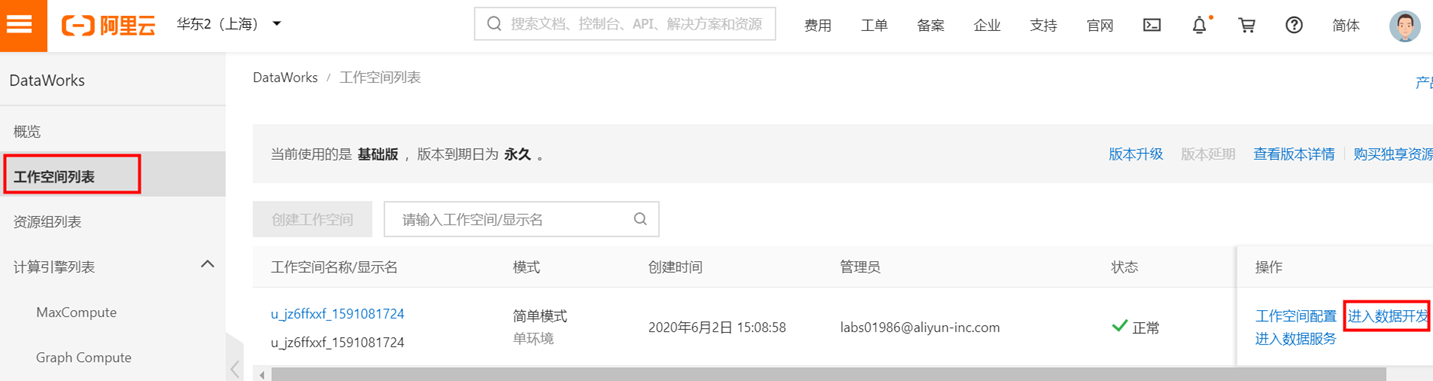
1)点击DataWorks进入DataWorks控制台,选择左侧栏工作空间列表,点击数据开发,然后选择数据集成,进入顶部菜单栏中的【数据集成】页面,点击左侧导航栏中的 【数据源】,再点击右上角的 【新增数据源】,如图:
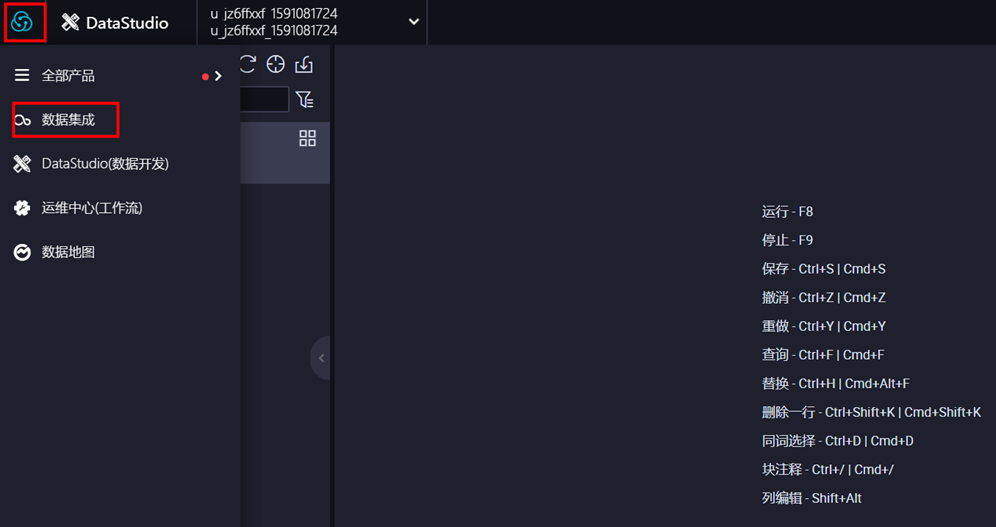
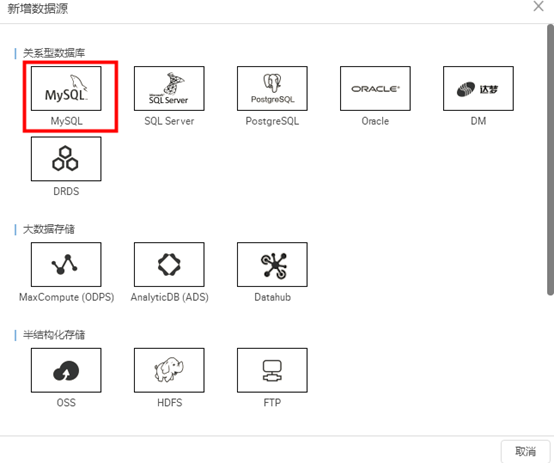
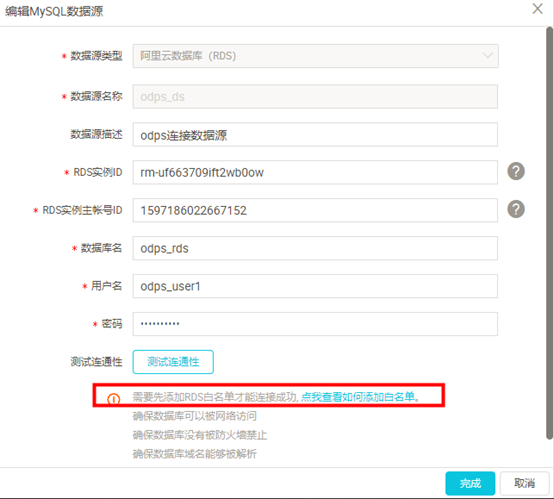
 2)选择关系型数据库“MySQL”, 在弹出框中填写相关配置项,并确认已添加白名单。然后点击【测试连通性】,若测试成功,点击【确定】即可。
2)选择关系型数据库“MySQL”, 在弹出框中填写相关配置项,并确认已添加白名单。然后点击【测试连通性】,若测试成功,点击【确定】即可。
注意:RDS实例相关信息可点击【实验资源】查看。RDS实例购买者ID需要填主账号ID(即企业别名);个人阿里云账户可参考下面3)、4)、5)步骤来获取相关信息
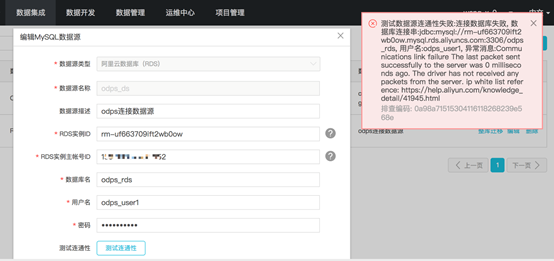
 新建或编辑数据源,相关信息填写完成后,(数据源名称根据业务自定义即可),点击“测试连通性”按钮。如果弹出右侧红色弹框,说明白名单设置有问题。
新建或编辑数据源,相关信息填写完成后,(数据源名称根据业务自定义即可),点击“测试连通性”按钮。如果弹出右侧红色弹框,说明白名单设置有问题。
 点击【点我查看如何添加白名单】,注意根据项目所在 Region 选择相应的白名单
点击【点我查看如何添加白名单】,注意根据项目所在 Region 选择相应的白名单
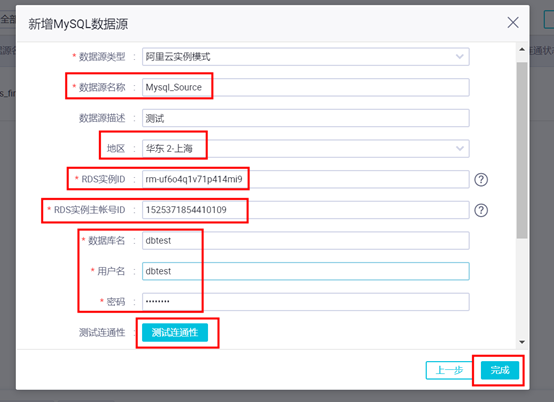
 环境、信息配置成功后,点击“测试连通性”会弹出右侧成功的提示,然后点击“完成”即可。
环境、信息配置成功后,点击“测试连通性”会弹出右侧成功的提示,然后点击“完成”即可。
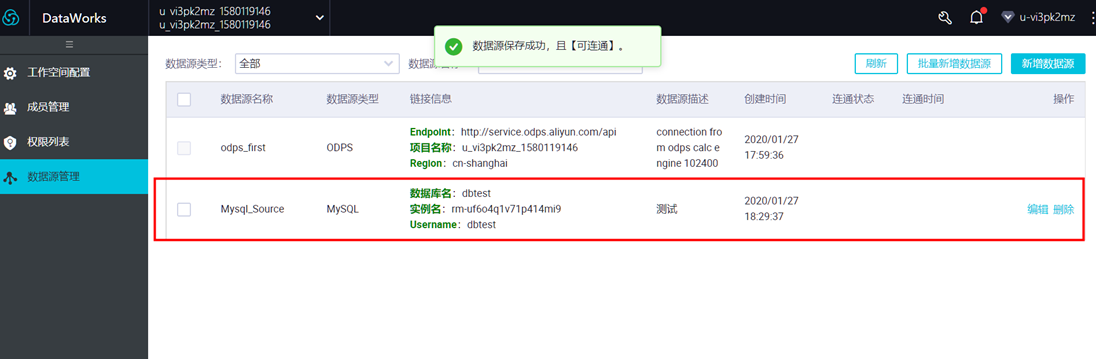 以下内容本实验不用进行,提供给个人账号操作使用
以下内容本实验不用进行,提供给个人账号操作使用
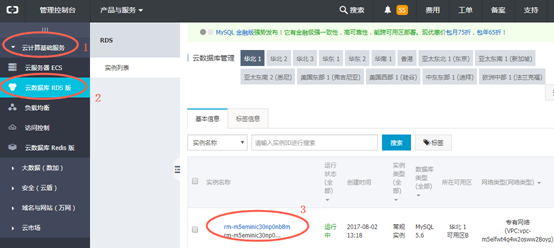
3)个人账号查看RDS实例ID
在【管理控制台】界面,点击左侧菜单栏【云计算基础服务】中的【云数据库RDS版】,在打开的实例列表中选中实例,点击查看实例信息。
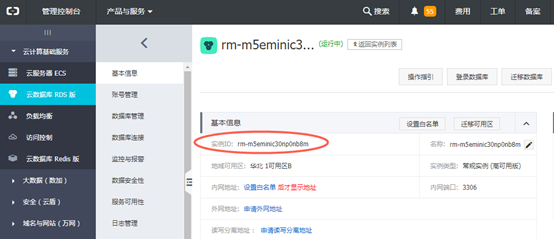 4) 个人账号查看RDS实例购买者ID
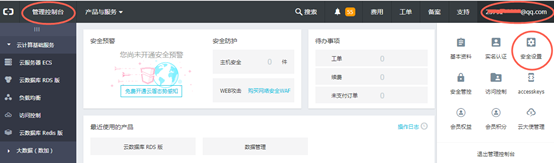
4) 个人账号查看RDS实例购买者ID
在【管理控制台】界面,点击右上角显示的登录账号,进入“安全设置”,查看”账号ID”
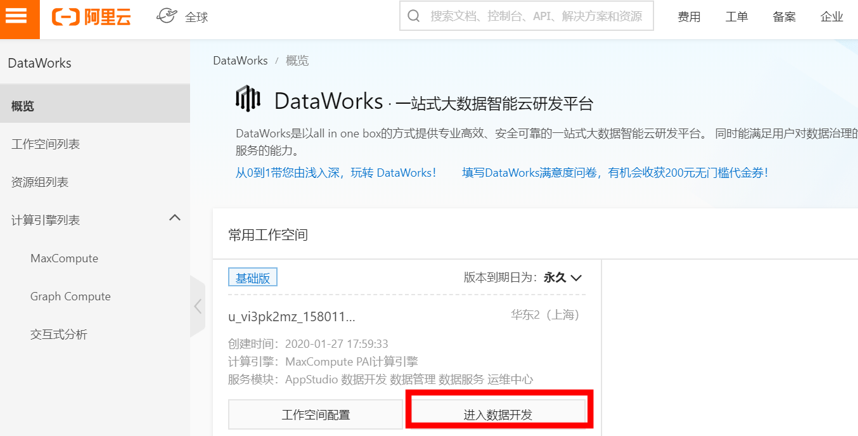
2.5 DataWorks数据同步
1)打开【管理控制台】,在左侧菜单栏中点击【大数据(数加)】,在下拉菜单中选择【DataWorks】,然后在项目列表中选中项目,点击【进入数据开发】。
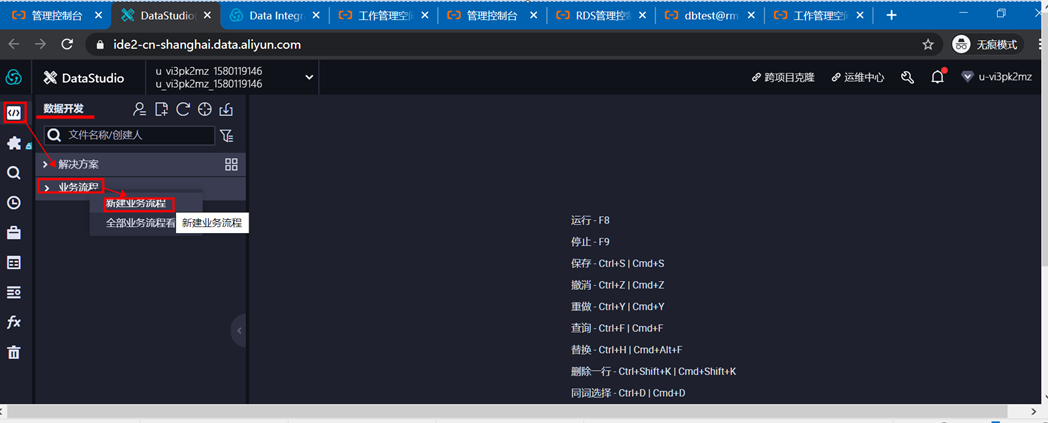
 2)点击左侧选项卡中的【任务开发】,然后点击【新建】,选择【新建业务流程】
2)点击左侧选项卡中的【任务开发】,然后点击【新建】,选择【新建业务流程】
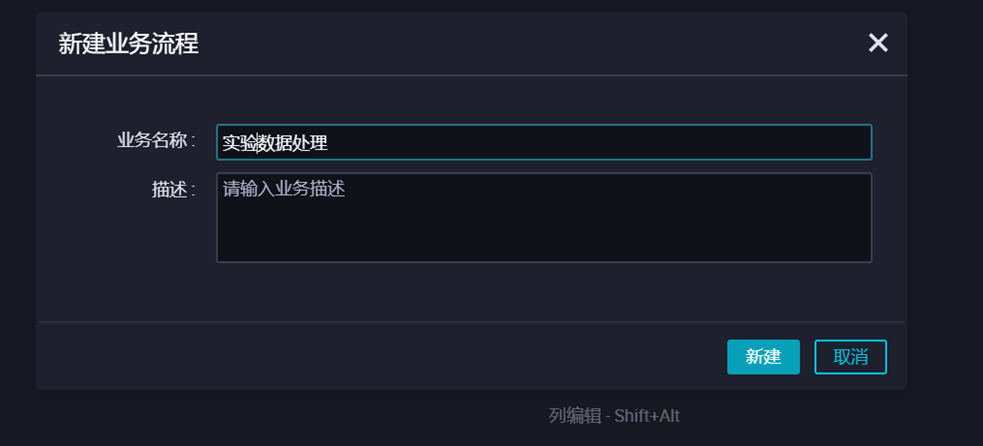
 3)输入业务名称,然后点击【新建】。
3)输入业务名称,然后点击【新建】。
说明:工作流任务是节点任务的集合,一个工作流任务中,可以创建多个节点任务,一个节点任务,可以完成一件事,而一个工作流任务,可以完成一个流程。
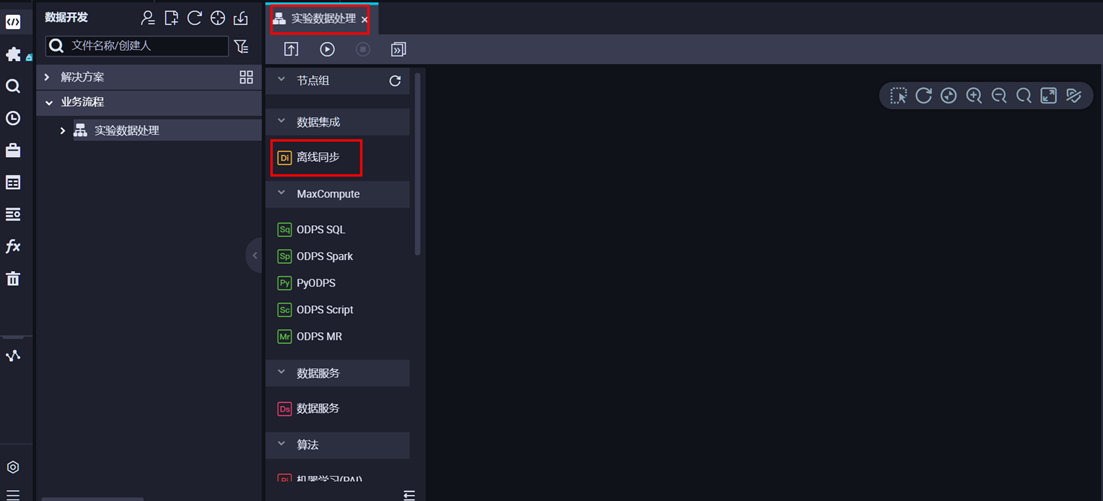
 4)在节点组件中选择【离线同步】,拖动到右侧画布中
4)在节点组件中选择【离线同步】,拖动到右侧画布中
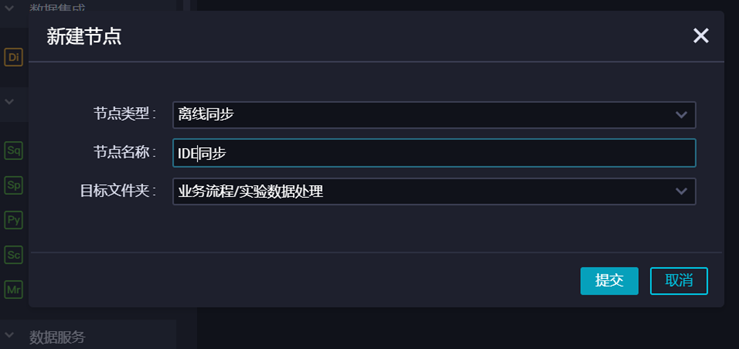
 然后输入“节点名称”,点击【提交】。
然后输入“节点名称”,点击【提交】。
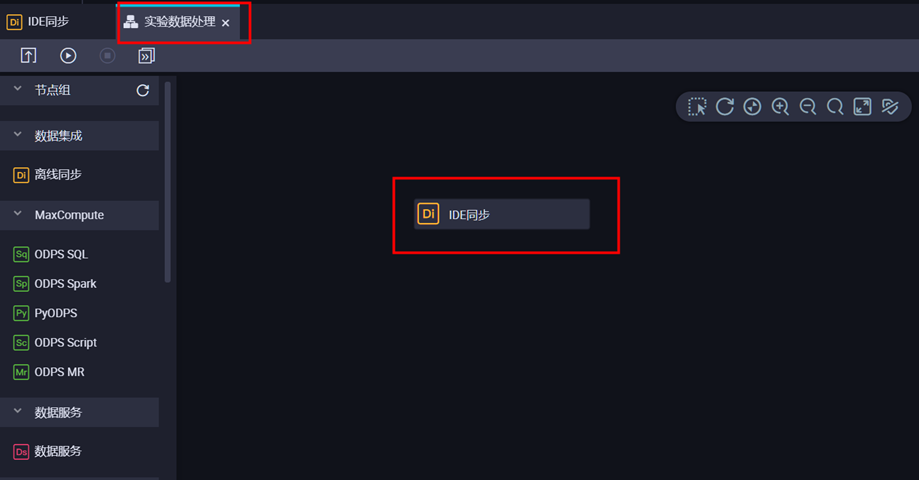 5)双击节点,进行数据同步设置。
5)双击节点,进行数据同步设置。
① 设置源表,数据源为“odps_ds(mysql)”,表名为“t_dml_data”,设置数据过滤条件"province<>'新疆'"。
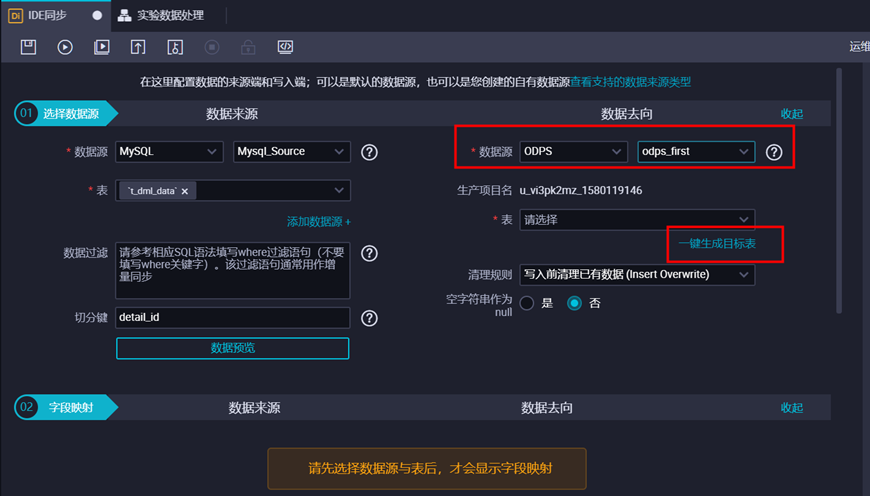
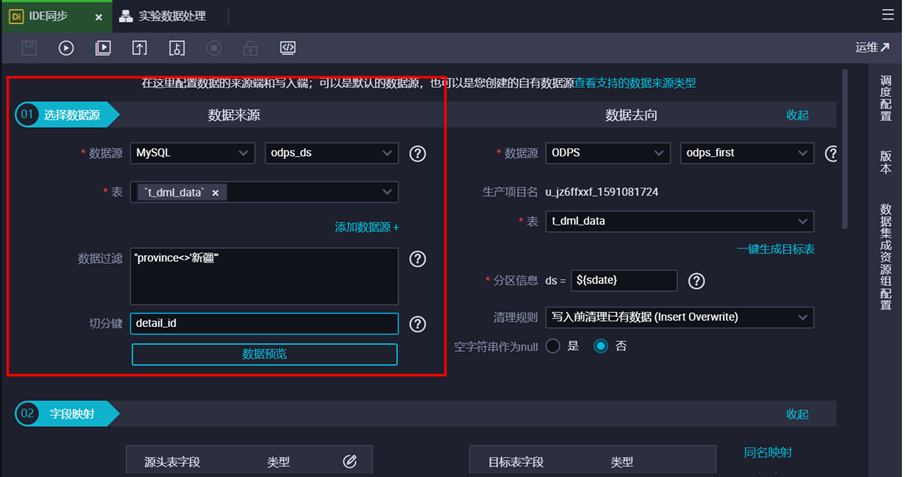 ② 设置目标表,数据源为“odps_first(odps)”,一键生成目标表(注意修改建表SQL的表名)
② 设置目标表,数据源为“odps_first(odps)”,一键生成目标表(注意修改建表SQL的表名)
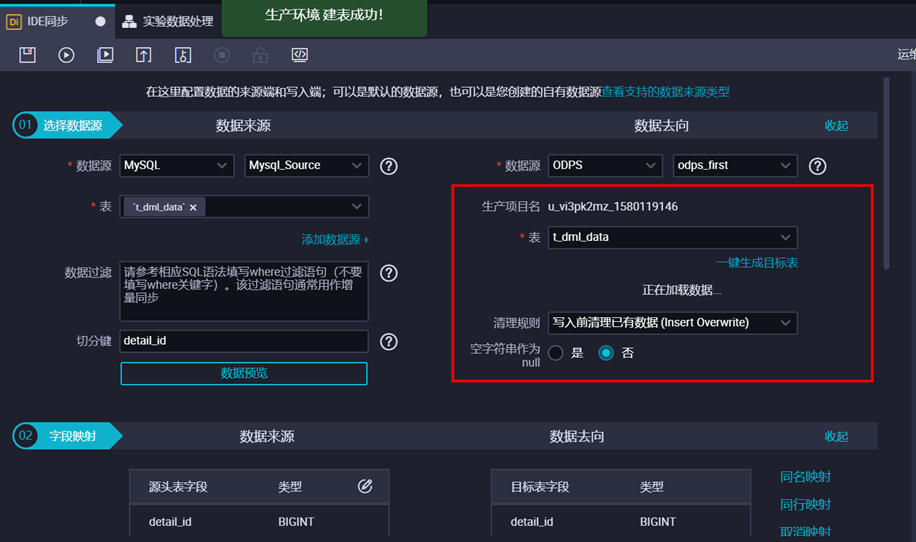
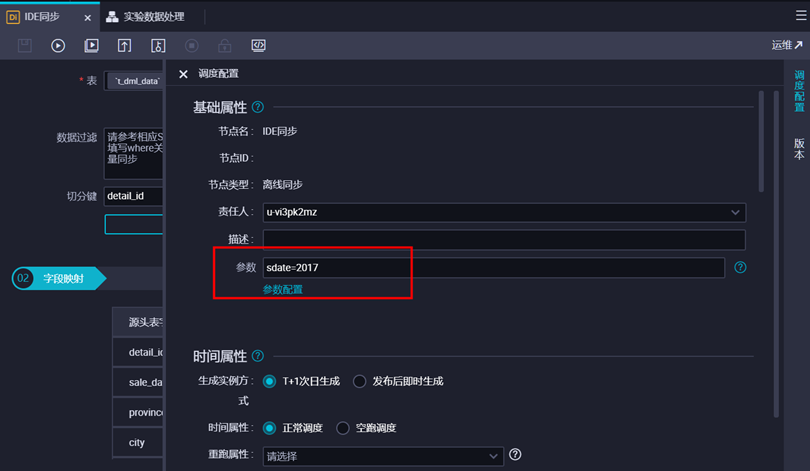
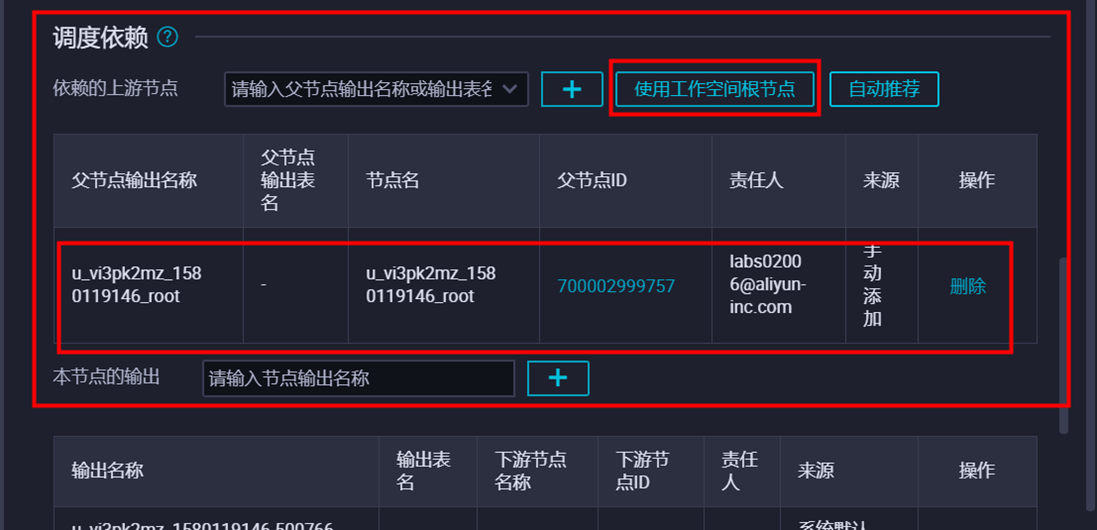
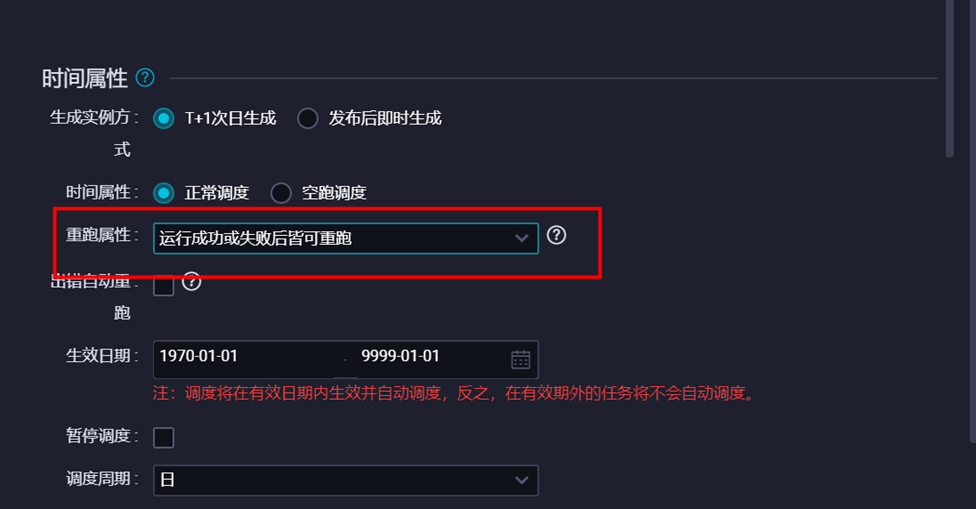
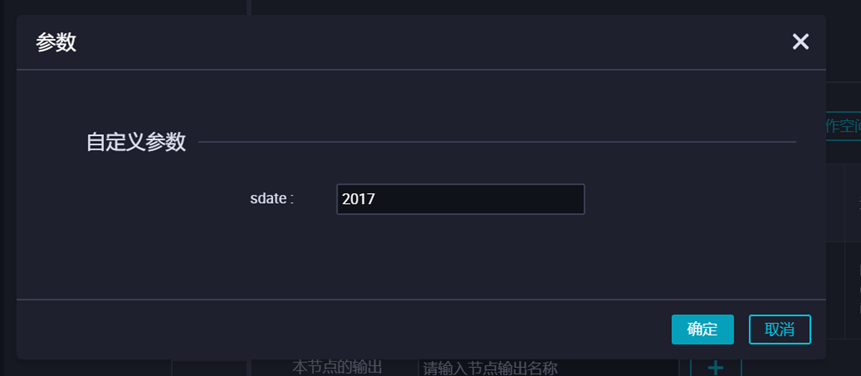
 填写目标表的分区信息。本示例中,分区为变量,ds=${sdate},在右侧【调度配置】中给该变量sdate赋值为常量‘2017’,选择清理规则【写入前清理已有数据 Insert Overwrite】,设置重跑属性为运行成功或失败皆可重跑,依赖上游节点选择使用工作空间根节点。
填写目标表的分区信息。本示例中,分区为变量,ds=${sdate},在右侧【调度配置】中给该变量sdate赋值为常量‘2017’,选择清理规则【写入前清理已有数据 Insert Overwrite】,设置重跑属性为运行成功或失败皆可重跑,依赖上游节点选择使用工作空间根节点。
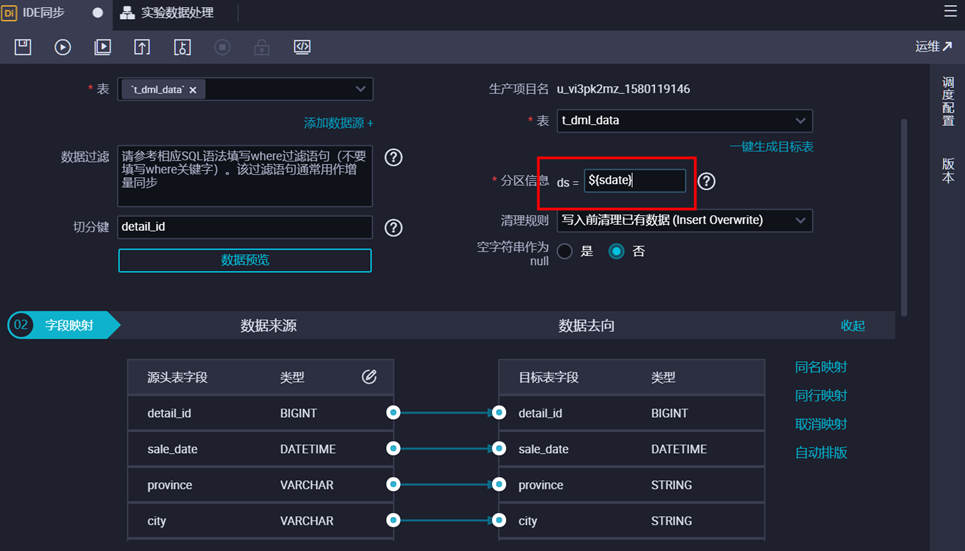
 ③ 字段映射。对字段映射关系进行配置,左侧源表字段和右侧目标表字段为一一对应的关系,并且与字段顺序无关。
③ 字段映射。对字段映射关系进行配置,左侧源表字段和右侧目标表字段为一一对应的关系,并且与字段顺序无关。
 ④ 设置通道控制信息。DMU是数据集成消耗资源的度量单位。本示例中设置任务并发数为“5”、不限流”、错误记录数超过“10条”,任务结束。然后进行下一步。
④ 设置通道控制信息。DMU是数据集成消耗资源的度量单位。本示例中设置任务并发数为“5”、不限流”、错误记录数超过“10条”,任务结束。然后进行下一步。
说明:如果数据源是线上的业务库,建议不要将并发数设置过大,以防对线上库造成影响;如果对数据同步速率特别在意,建议选择较大的作业并发数。
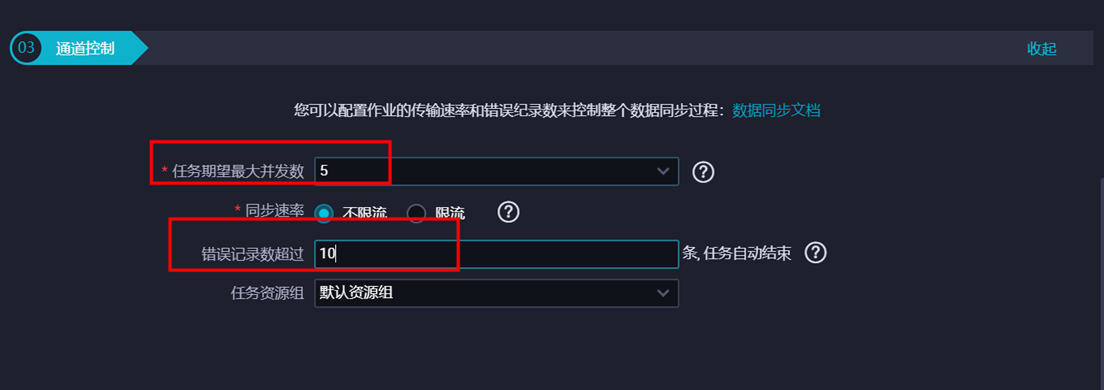 ⑤ 配置完成后,预览信息,如无误,点击【保存】。
⑤ 配置完成后,预览信息,如无误,点击【保存】。
 6)同步数据。
6)同步数据。
节点设置完成后,点击【运行】,带参数测试运行。
 选择业务日期,然后点击【运行】。因是一次性调度,而且抽取源表数据时,不是按时间设置数据过滤条件,故此处的业务日期选择2017。
选择业务日期,然后点击【运行】。因是一次性调度,而且抽取源表数据时,不是按时间设置数据过滤条件,故此处的业务日期选择2017。
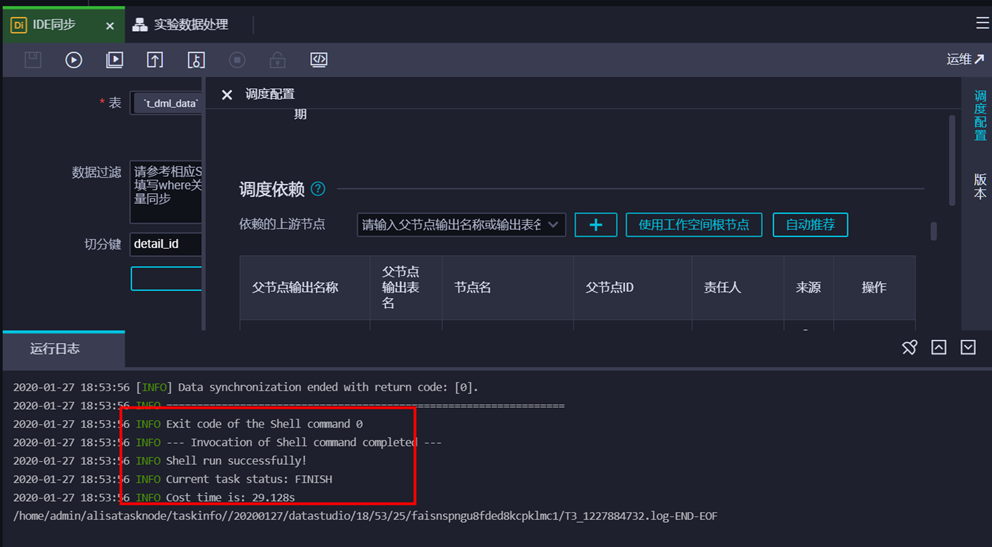
 7)查看同步结果
7)查看同步结果
当数据同步完成后,状态变为“成功”:
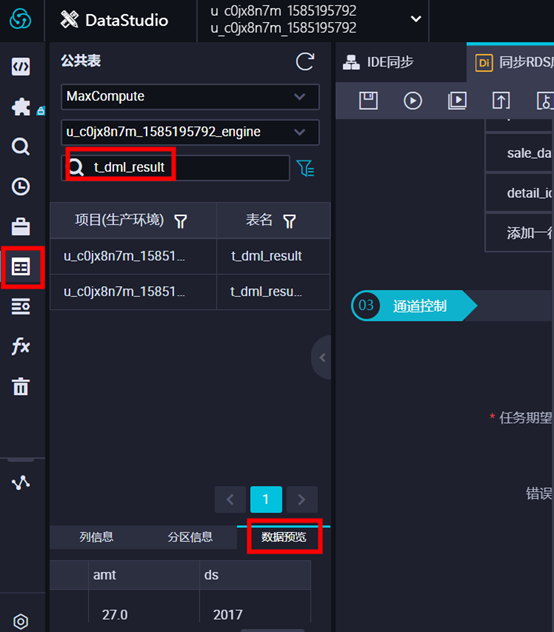
 预览表数据。在左侧栏中,点击公共表,搜索表名,然后选中数据表t_dml_data,点击【数据预览】即可看到数据,或点击临时查询,新建ODPS SQL,根据下图通过SQL语句查询数据。
预览表数据。在左侧栏中,点击公共表,搜索表名,然后选中数据表t_dml_data,点击【数据预览】即可看到数据,或点击临时查询,新建ODPS SQL,根据下图通过SQL语句查询数据。
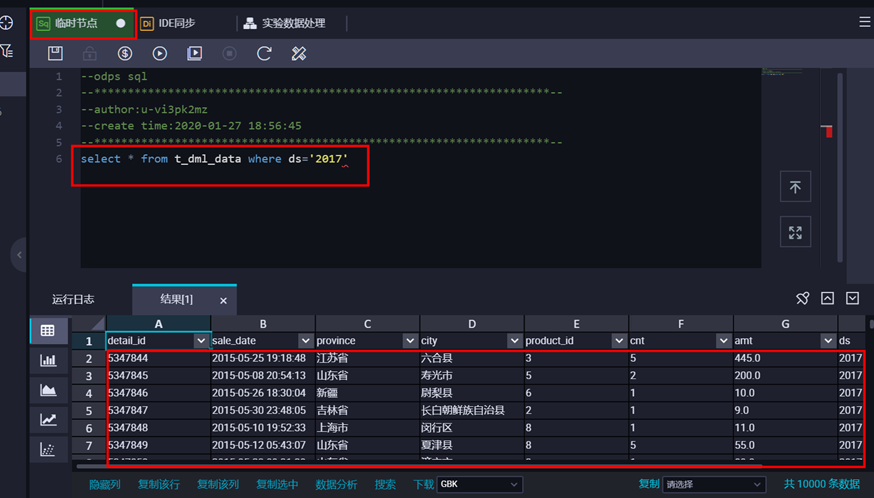 数据导入成功。
数据导入成功。
2.6 DataWorks数据开发
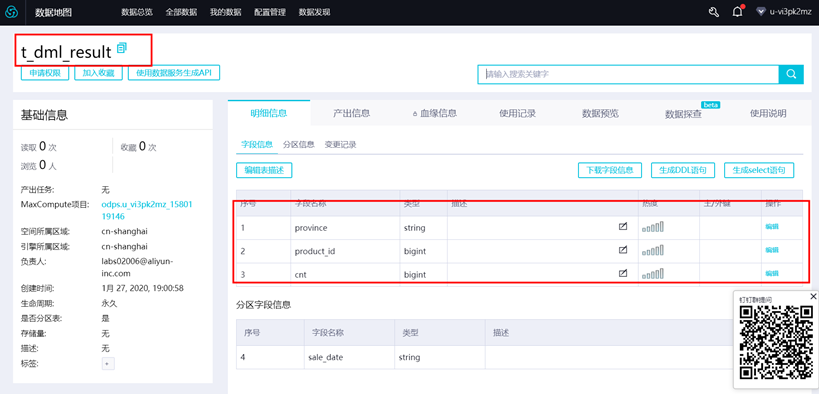
1、创建数据表 创建目标表t_dml_result,用于存储数据分析后产生的结果。步骤如下:
点击顶部菜单栏中的【临时查询】,然后点击【新建】,选择【ODPS SQL】;
 输入节点名称,点击【提交】,然后输入建表语句建表。
输入节点名称,点击【提交】,然后输入建表语句建表。
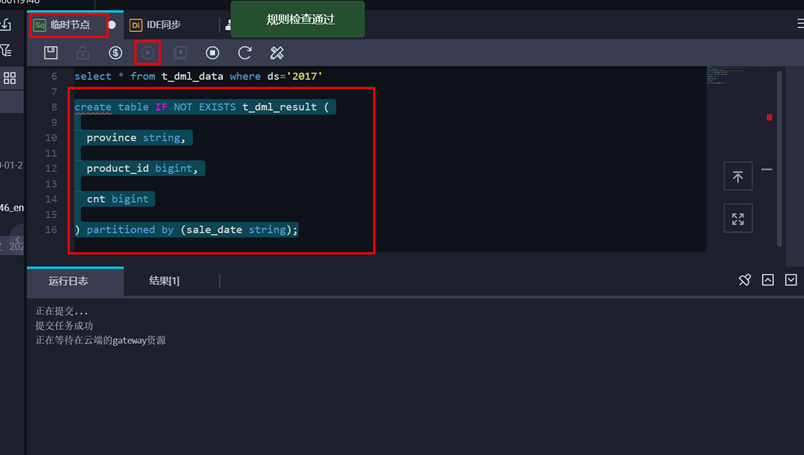 建表语句如下:
建表语句如下:
create table IF NOT EXISTS t_dml_result (
province string,
product_id bigint,
cnt bigint
) partitioned by (sale_date string);
创建表后,可以在左侧导航栏【表查询】中,输入表名进行搜索,查看表信息。如下图所示:
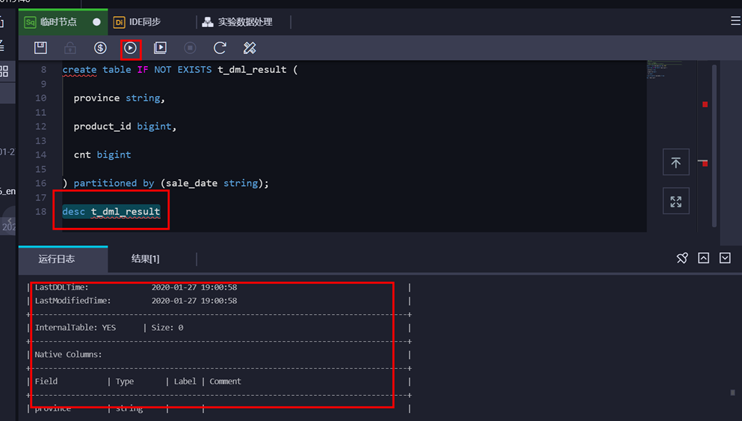
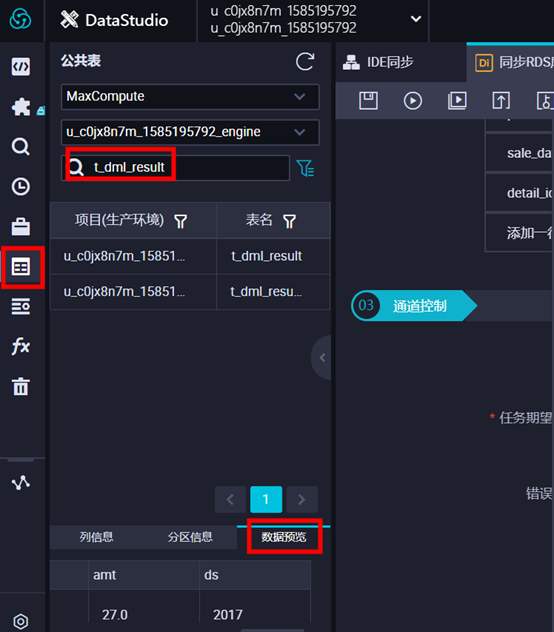 或者输入如下语句进行检查表 desc t_dml_result
或者输入如下语句进行检查表 desc t_dml_result
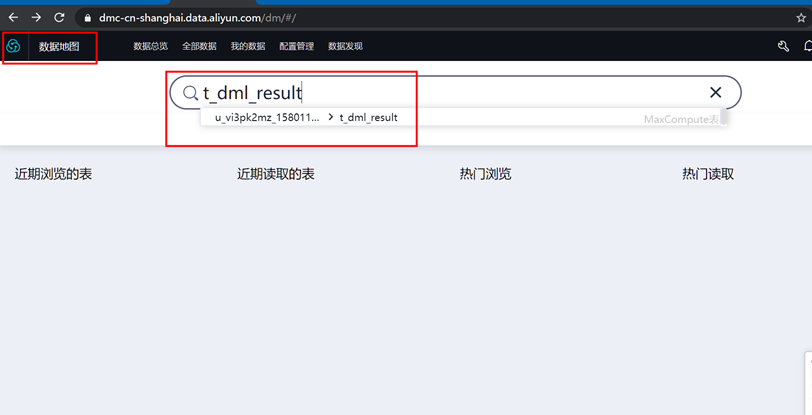
 或者通过数据地图查看数据表信息。以上三种方法三选一即可。
或者通过数据地图查看数据表信息。以上三种方法三选一即可。
 2、 创建SQL任务
点击顶部菜单栏中的【临时查询】,然后点击【新建】,选择【新建ODPS SQL】;
2、 创建SQL任务
点击顶部菜单栏中的【临时查询】,然后点击【新建】,选择【新建ODPS SQL】;
 在弹出框中,输入节点名称,然后点击【提交】;
在弹出框中,输入节点名称,然后点击【提交】;
双击节点对节点进行配置,新版本不许全表扫描,所以要增加设置:全表扫描。
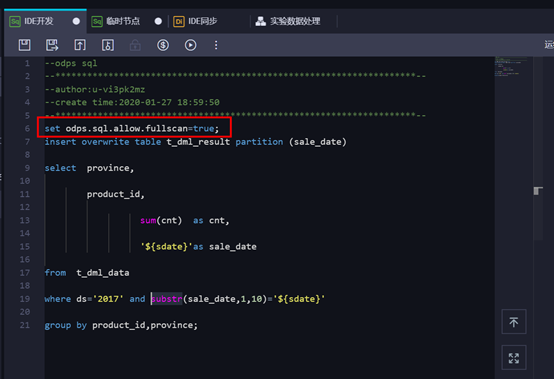 在节点中编写好SQL语句后,点击右侧菜单选项进行“自定义参数配置”,然后点击【保存】并 【提交】。
在节点中编写好SQL语句后,点击右侧菜单选项进行“自定义参数配置”,然后点击【保存】并 【提交】。
说明:只有提交过的任务才能被调度执行。
注意:下图中的调度类型一旦选定,不可再更改
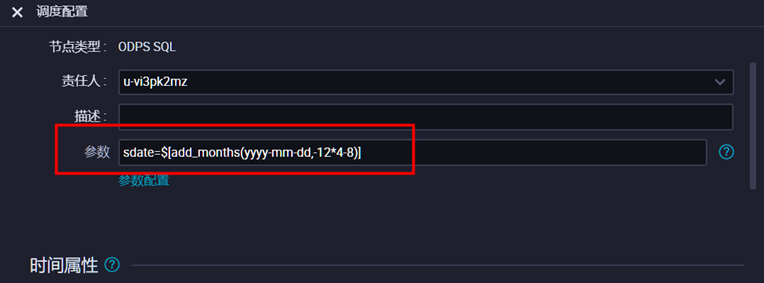 自定义参数配置:$[add_months(yyyy-mm-dd,-12*4-8)]
自定义参数配置:$[add_months(yyyy-mm-dd,-12*4-8)]
说明:因源表t_dml_data中数据时间为2015年5月,而调度执行时间为2020年1月,故参数需往前推4年零8个月。
需根据实际实验时间修改参数设置。
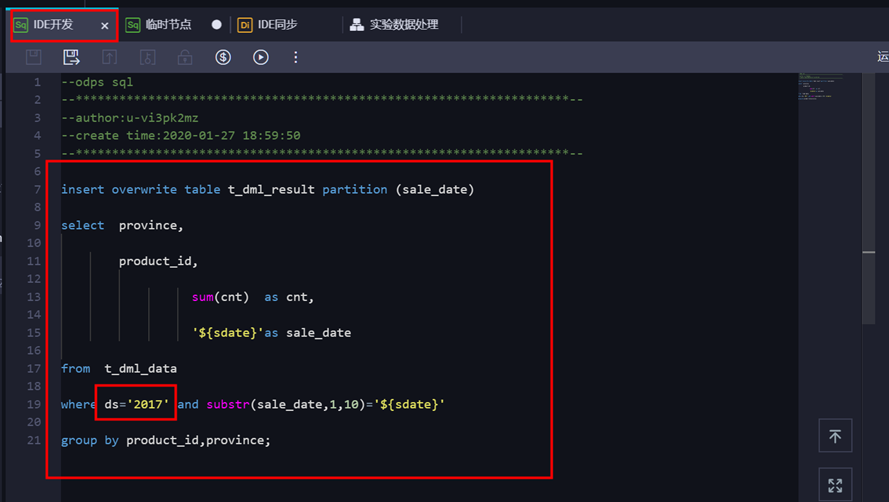
本SQL实现按省份和产品维度,对每天的销售量进行汇总。代码如下:
insert overwrite table t_dml_result partition (sale_date)
select province,
product_id,
sum(cnt) as cnt,
'${sdate}'as sale_date
from t_dml_data
where ds='2017' and substr(sale_date,1,10)='${sdate}'
group by product_id,province;
配置完成后,注意依赖关系:
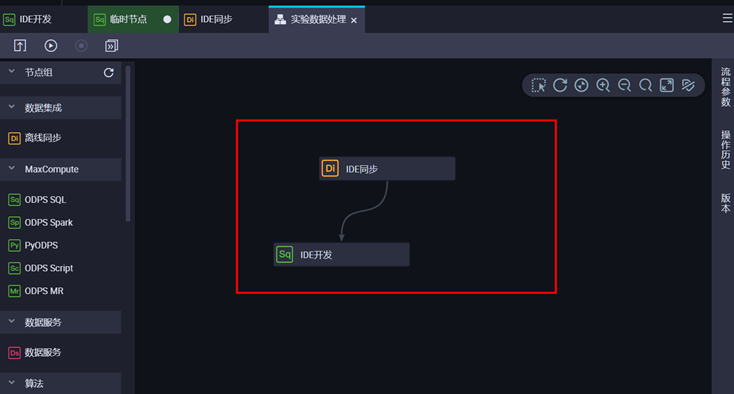
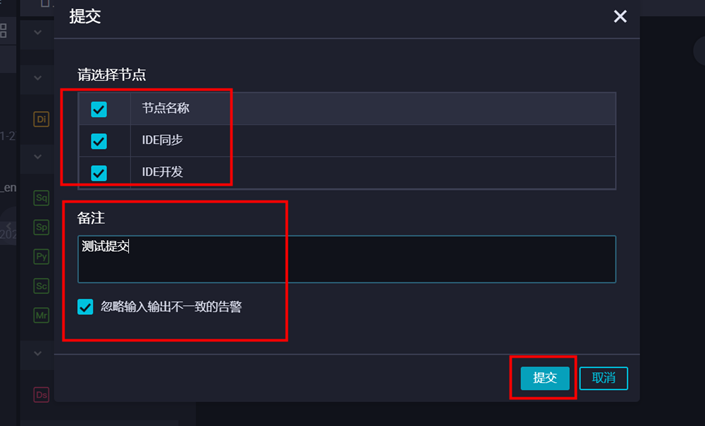
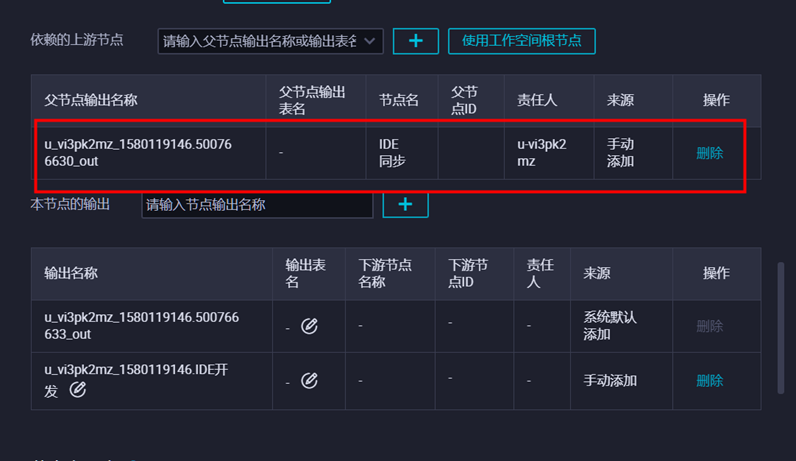 然后点击提交,开始运行节点。
然后点击提交,开始运行节点。
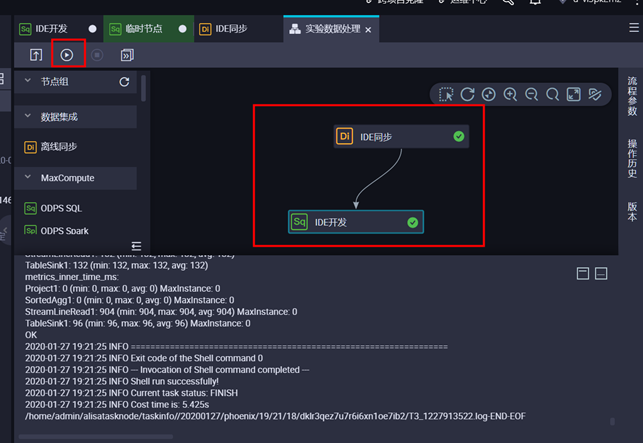 检查表信息,在临时节点输入sql检查语句 set odps.sql.allow.fullscan=true; select * from t_dml_result
检查表信息,在临时节点输入sql检查语句 set odps.sql.allow.fullscan=true; select * from t_dml_result
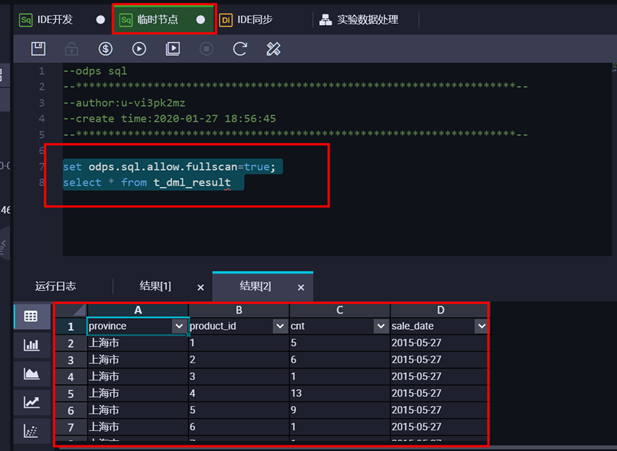 3 、本地数据上传
在前面章节中,我们通过数据同步的方式获取了数据源。如果直接从本地文件导入到MaxCompute呢,又该如何操作?
3 、本地数据上传
在前面章节中,我们通过数据同步的方式获取了数据源。如果直接从本地文件导入到MaxCompute呢,又该如何操作?
1)建表
① 在【临时查询】页面点击【新建】,选择【ODPS SQL】。
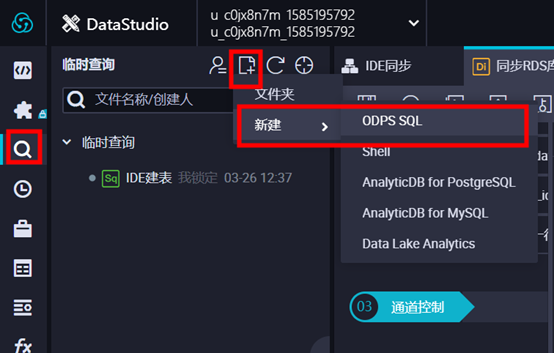 ② 输入节点名称,点击“提交”。
② 输入节点名称,点击“提交”。
③ 输入建表语句,并点击【运行】
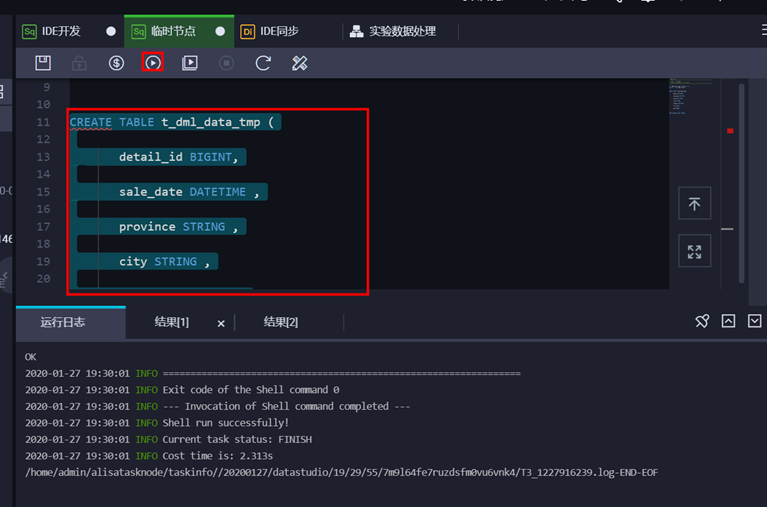 建表语句如下:
建表语句如下:
CREATE TABLE t_dml_data_tmp (
detail_id BIGINT,
sale_date DATETIME ,
province STRING ,
city STRING ,
product_id BIGINT,
cnt BIGINT ,
amt DOUBLE
)
PARTITIONED BY (pt STRING);
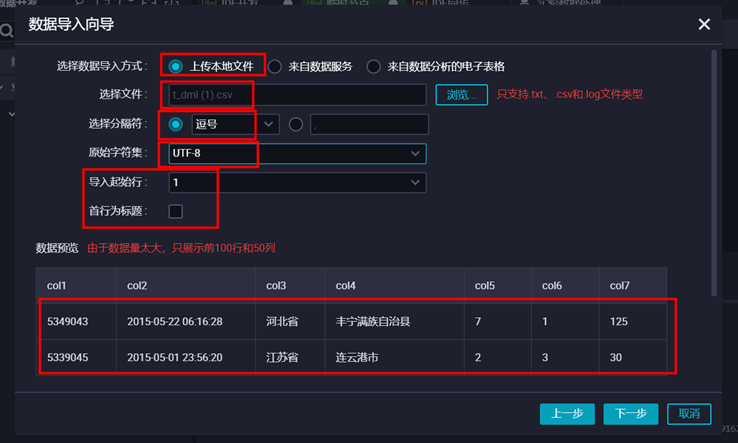
2)上传数据
- 点击顶部菜单栏的【数据开发】,然后进行数据导入
2 选择分隔符号“逗号”、原始字符集“UTF-8”、导入起始行“1”,并且去掉首行为标题的勾勾,然后点击【下一步】。
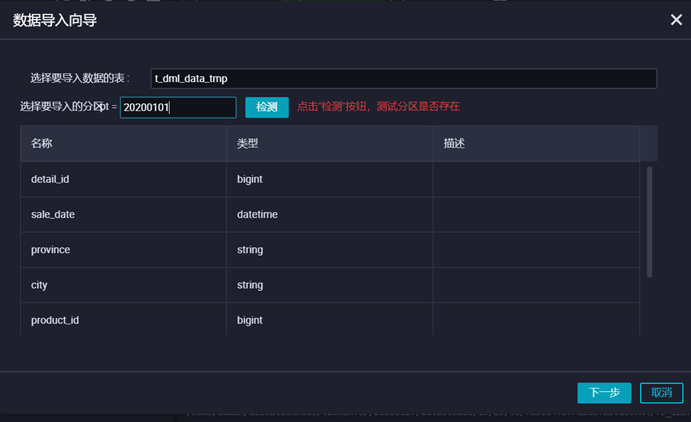
 2. 输入表名及分区,点击【导入】。
2. 输入表名及分区,点击【导入】。
 3. 导入成功后,查看数据结果。
3. 导入成功后,查看数据结果。
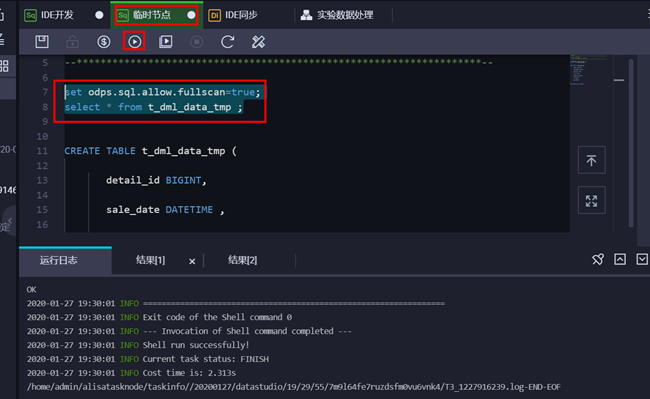 执行SQL语句如下:
执行SQL语句如下:
set odps.sql.allow.fullscan=true;
select * from t_dml_data_tmp;
查看结果如下:
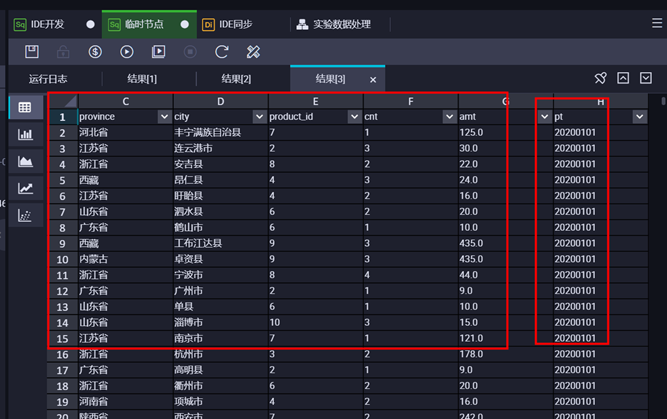
4 、数据表管理 点击菜单栏【表管理】,可以查看表信息。
① 查看表
点击【生产账号的表】选项卡,搜索表名,点击表“t_dml_data_tmp”即可查看表的详情信息。
 ② 收藏表
② 收藏表
通过菜单栏中数据地图进入数据管理页面,在表详情页搜索表名称可以查看表,点击【收藏】即可,也可在此单击【取消收藏】。
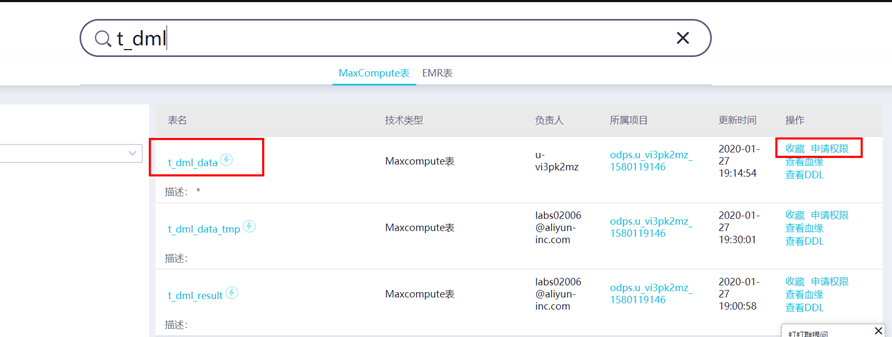 ③ 表权限申请
③ 表权限申请
在表详情页中点击权限管理,可进行权限申请。
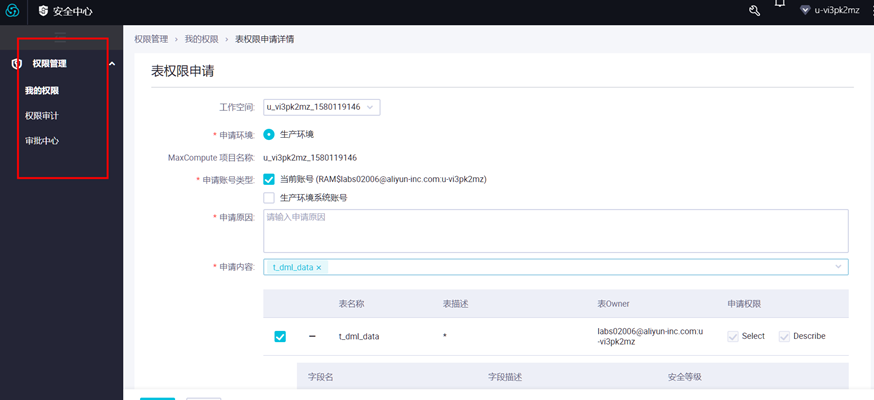 填写申请授权弹出框中的各配置项,点击【确定】提交,然后等待审批。如下图所示:
填写申请授权弹出框中的各配置项,点击【确定】提交,然后等待审批。如下图所示:
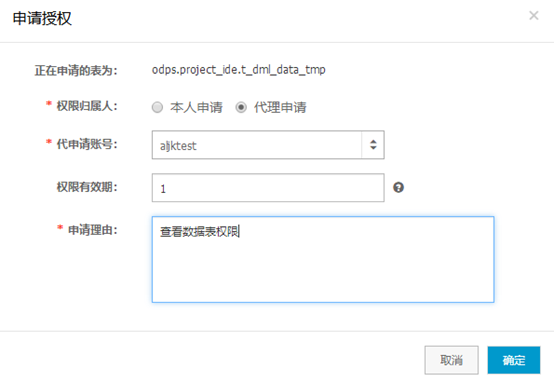 说明:
说明:
权限归属人:支持本人申请和代理申请。
本人申请:选择该项,审批通过后权限归属于当前用户。
代理申请:选择代理申请,需填写代申请账号(系统右上角显示的登录名)。审批通过后权限归属于被代理人。
权限有效期:申请表权限的时长,单位为天,不填则默认为永久。超过申请权限时长时,该权限将被系统自动回收。
申请理由:请简要填写申请理由以便更快地通过审批。
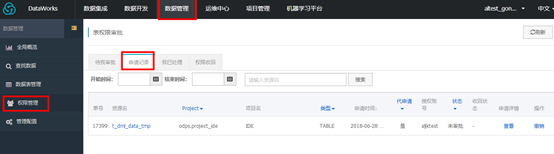
可在【数据管理】>【权限管理】> 【申请记录】中查看申请状态。
2.8 任务运维
1 、运维中心 有两种方式可进入运维中心界面。
方式一:在数据开发页面,点击左上角【前往运维】,进入后即可查看到运维大屏。
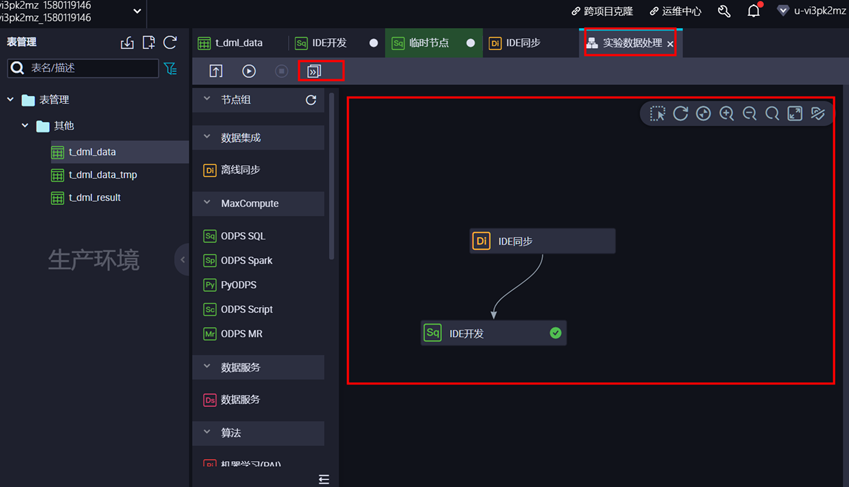
 2、 任务列表
点击左侧菜单栏中的【任务列表】,选择“任务类型”和“责任人”,可对任务进行筛选。
2、 任务列表
点击左侧菜单栏中的【任务列表】,选择“任务类型”和“责任人”,可对任务进行筛选。
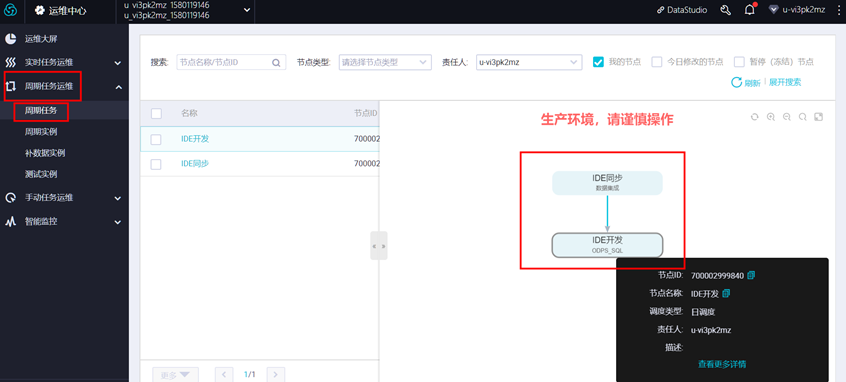 选中某个任务,可执行“测试”、“补数据”等操作。
选中某个任务,可执行“测试”、“补数据”等操作。
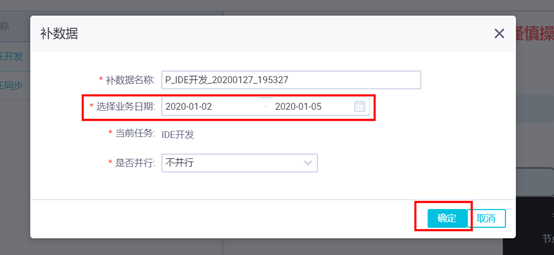
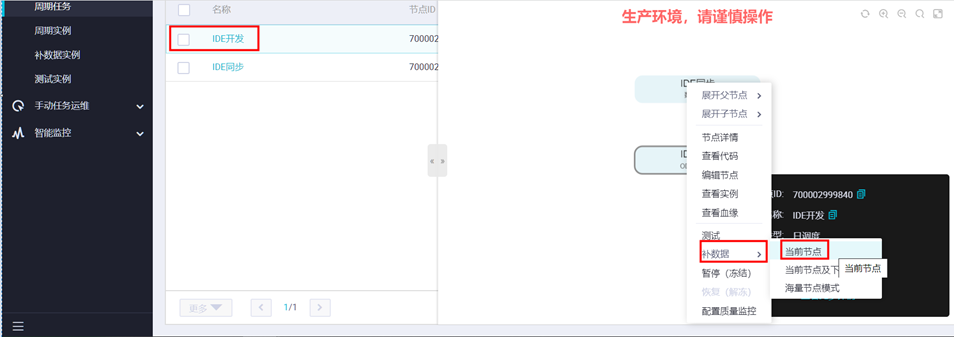 如点击“补数据”,可补历史数据。
如点击“补数据”,可补历史数据。
本例中将演示补2015-5-2和2015-5-3日的数,则会按天生成2个实例。
如下图,设置业务日期为2017-08-01至2017-08-02,点击【确定】,并【确认】。
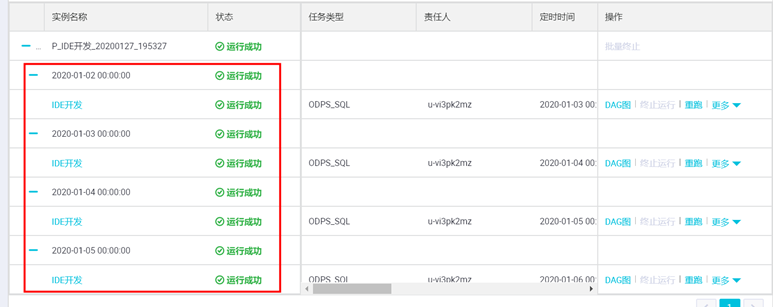
 自动跳转至【补数据实例】页面,等待状态由“运行中”变为“成功”。
自动跳转至【补数据实例】页面,等待状态由“运行中”变为“成功”。
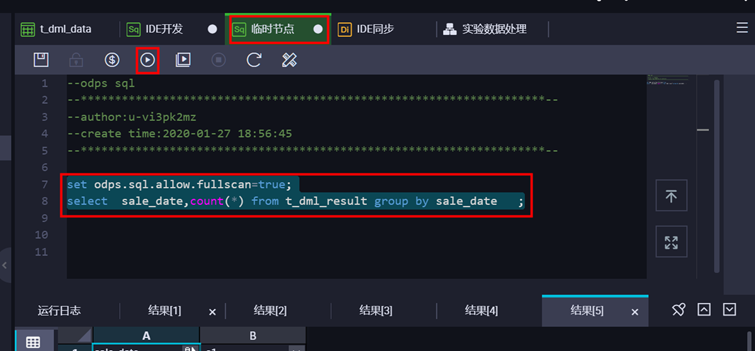
 如要验证补数结果,可前往“数据开发”页面查询表数据,通过如下语句:set odps.sql.allow.fullscan=true; select sale_data,count(*) from t_dml_result group by sale_data;。
如要验证补数结果,可前往“数据开发”页面查询表数据,通过如下语句:set odps.sql.allow.fullscan=true; select sale_data,count(*) from t_dml_result group by sale_data;。
 3 、任务运维
选中左侧菜单栏中的【任务运维】选项卡,点击相应实例,可重跑任务。下图以【补数据实例】为例说明:
3 、任务运维
选中左侧菜单栏中的【任务运维】选项卡,点击相应实例,可重跑任务。下图以【补数据实例】为例说明:
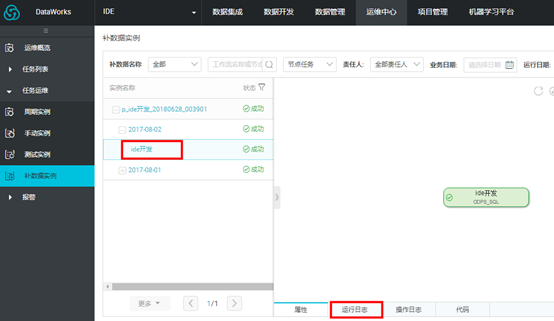
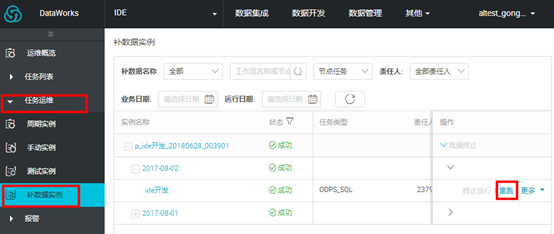 点击任务,可以查看任务运行日志。
点击任务,可以查看任务运行日志。
第 3 章:课后作业
3.1 课后作业
在实际场景中,作为生产系统,数据每时每刻都在发生。那么在本实验中,要把新产生的数据从RDS同步到MaxCompute进行大数据处理,如何改进更合理?
答案供参考:
1、“IDE同步”任务的调度类型需改为“周期性调度”;
2、源表数据抽取时,根据时间设置“数据过滤”条件;
3、目标表的分区,由常量改为变量;
4、“IDE开发”中where条件加分区,避免全表扫描;
5、控制同步任务的速率以及作业并发数。
第 4 章:课后练习
4.1 课后任务
1、创建一个周期性调度的数据同步任务(数据每天增量抽取);
2、在调度配置中,将跨周期依赖设置为“自依赖”,看看实验效果;



评论